
Here are six ways to remove a single column from a data frame in R:
- By assigning NULL to a specific column
- Removing a column by subsetting
- Deleting by column index
- Using subset()
- Using dplyr
- Using data.table
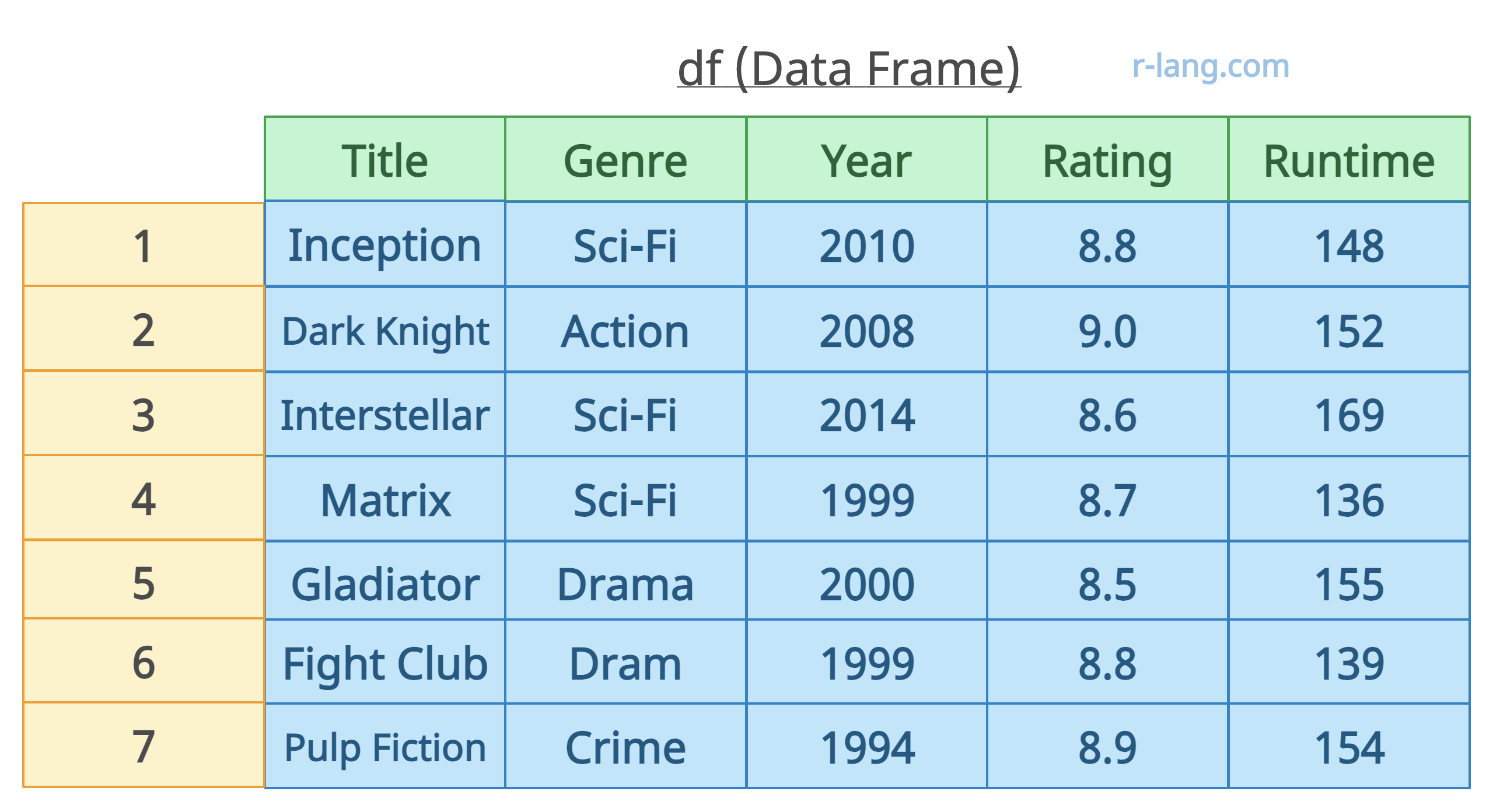
Here is the data frame for the practical:
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)Output
Method 1: Assigning NULL to a specific column
If you know the column you need to remove, you can simply use its name to select and assign NULL to it, and then that column will be removed.
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Deleting a Single Column
df$Runtime <- NULL
print(df)
Output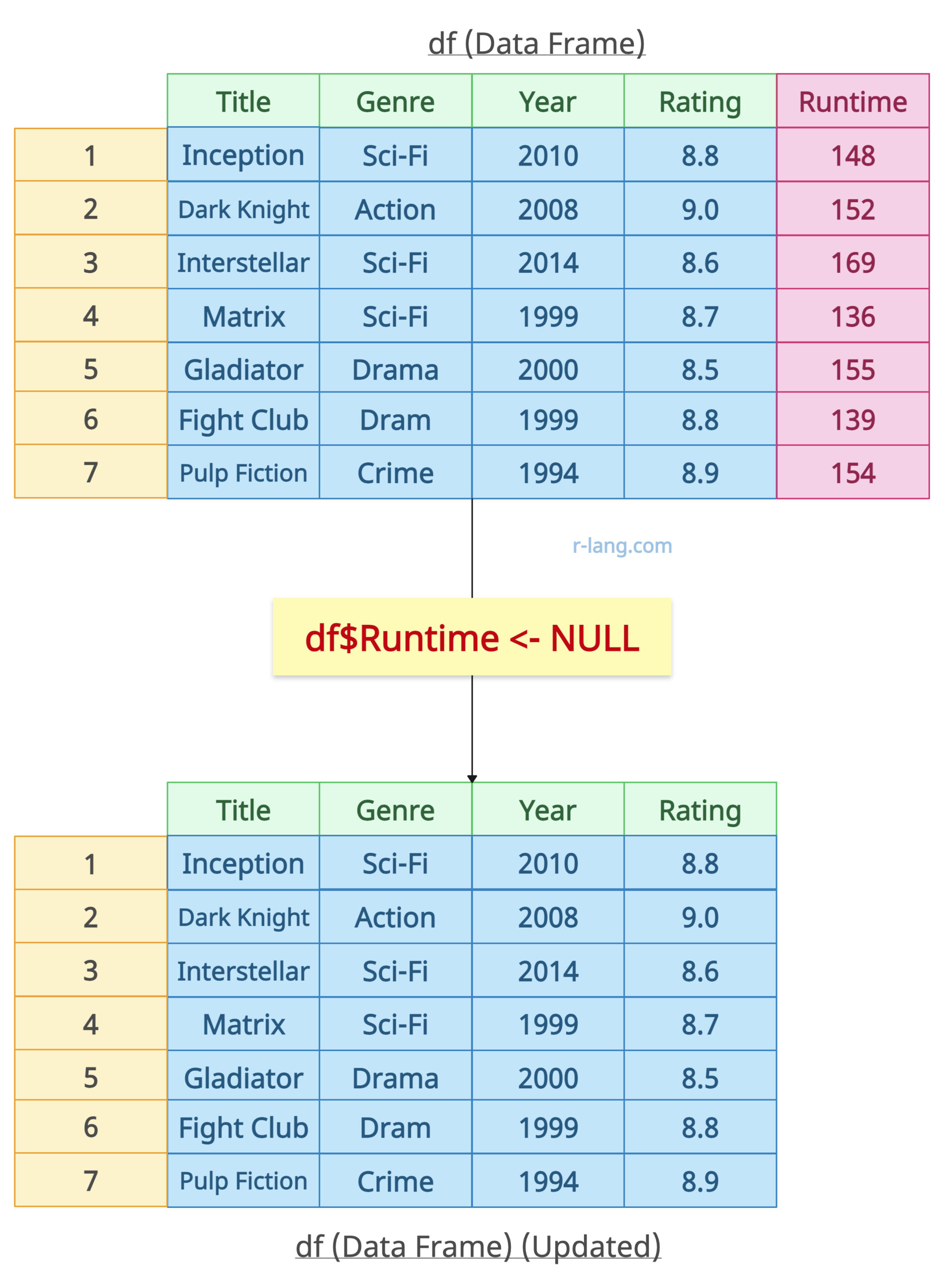
The above screenshot of the output shows that, in the updated data frame, the column “Runtime” has been removed because its value became NULL.
If the column does not exist, it won’t throw any errors. It fails silently.
Method 2: Removing a column by subsetting
You can subset using column names with the %in% operator, names() function, and ! operator.
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Removing single column by name
df <- df[, !names(df) %in% "Runtime"]
print(df)
Output
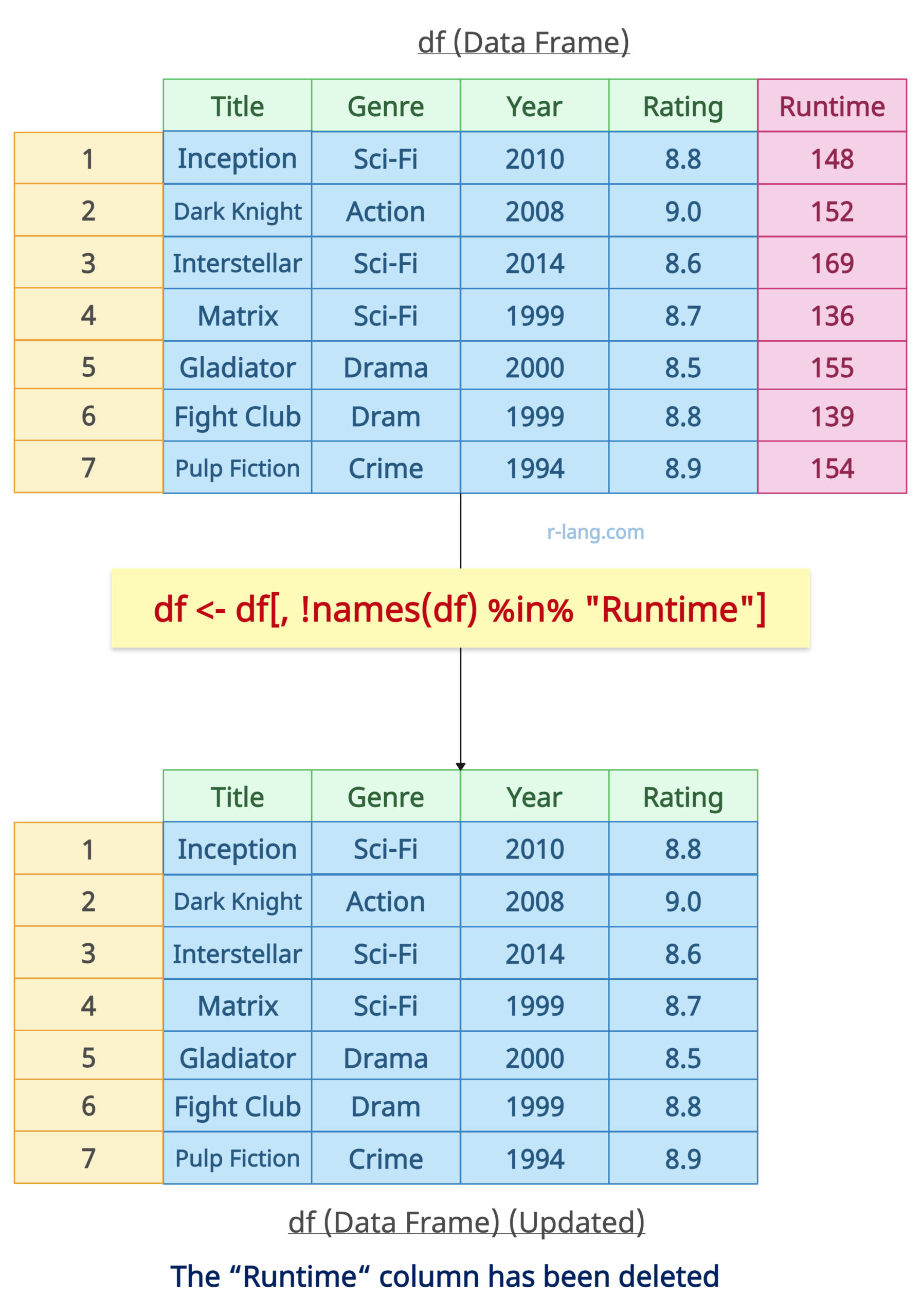
If you are looking for programmatic deletion, this approach might be very helpful.
Method 3: Deleting by column index
The column index starts from 1. If you know the specific column index for removal, you can use it by position.
Let’s remove the fifth column, which is “Runtime”. To remove that column, use the hyphen (-) before the column name.
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Removing single column by index
df <- df[, -5]
print(df)
Output

In this code, we are selecting a column whose index is 5. By passing -5, we instruct R to remove this column and, using <-, assign the remaining columns to the existing data frame, then print that data frame.
Method 4: Using subset()
The subset() function accepts a data frame and the select argument. You need to pass the -column_name value as the select argument, which means you have to remove that column.
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Using subset() function
df <- subset(df, select = -Runtime)
print(df)
Output

Method 5: Using dplyr
The dplyr package provides a select() function that accepts single or multiple columns, preceded by a hyphen (-) sign, to remove them. For example, df %>% select(-Runtime) will remove the Runtime column from the data frame.
library(dplyr)
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
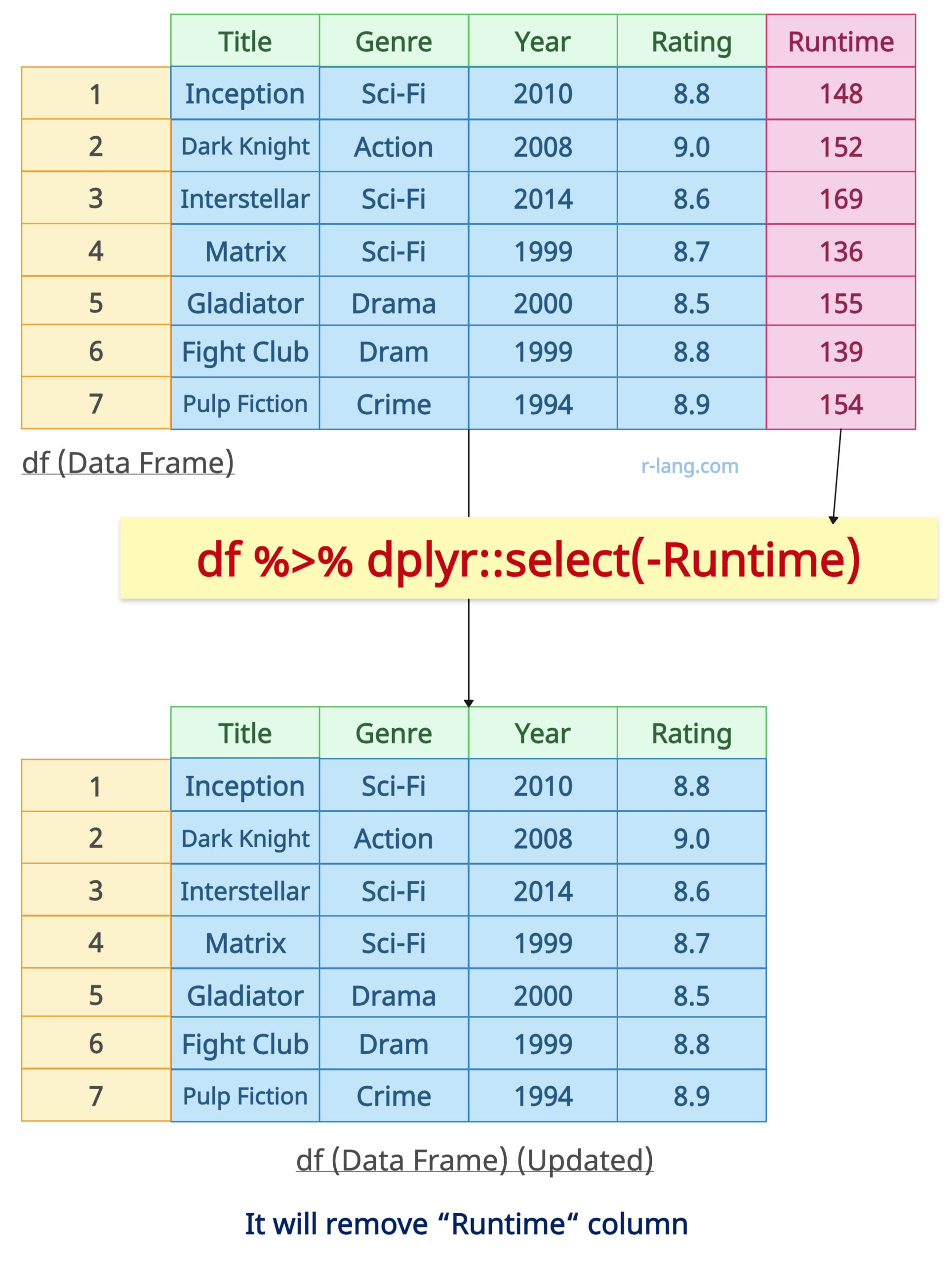
# Using dplyr to remove a column
df <- df %>% select(-Runtime)
print(df)
Output
Method 6: Using data.table
If you are working with large datasets, you should use the data.table because it has efficient in-place deletion that you can use.
# Using data.table
library(data.table)
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
setDT(df)
df[, Rating := NULL] # Assigning NULL to "Rating" column for the removal
print(df)
Output
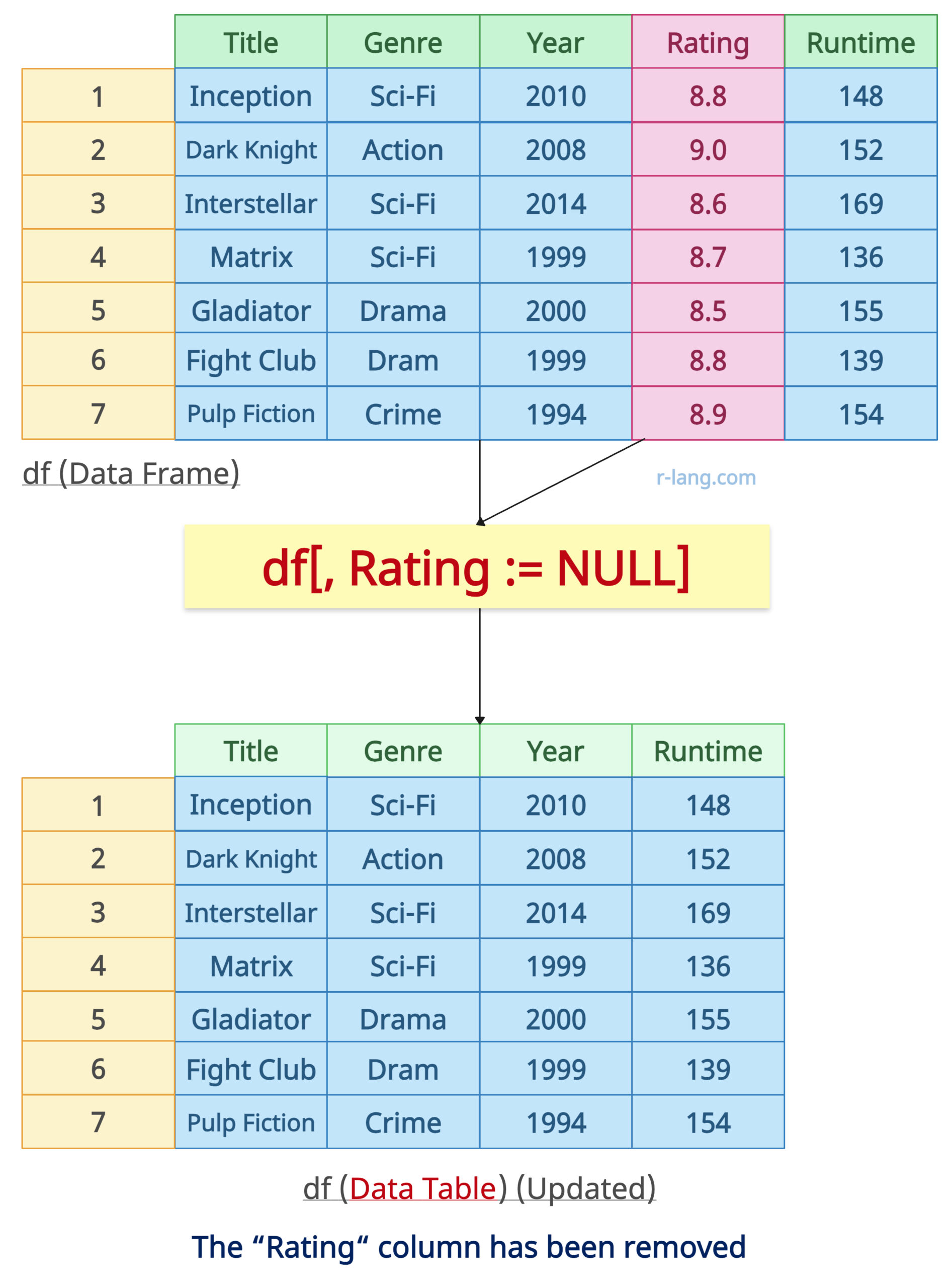 In this code example, first, we converted our input data frame into a data table using the setDT() function and then assigned NULL to the “Rating” column to remove it from the data table and finally printed it.
In this code example, first, we converted our input data frame into a data table using the setDT() function and then assigned NULL to the “Rating” column to remove it from the data table and finally printed it.
Here are five ways to remove multiple columns from a data frame:
- Removing multiple columns by subsetting a vector of columns
- Subsetting using column indices
- Use within() function
- Using dplyr
- Deleting the range of columns
Method 1: Removing multiple columns by subsetting a vector of columns
In this approach, define a vector of columns you want to remove and pass that while we are subsetting a data frame. It is the most straightforward approach.
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Delete Multiple Columns
# Subsetting using vector of columns
df <- df[, !names(df) %in% c("Year", "Runtime", "Rating")]
print(df)
Output
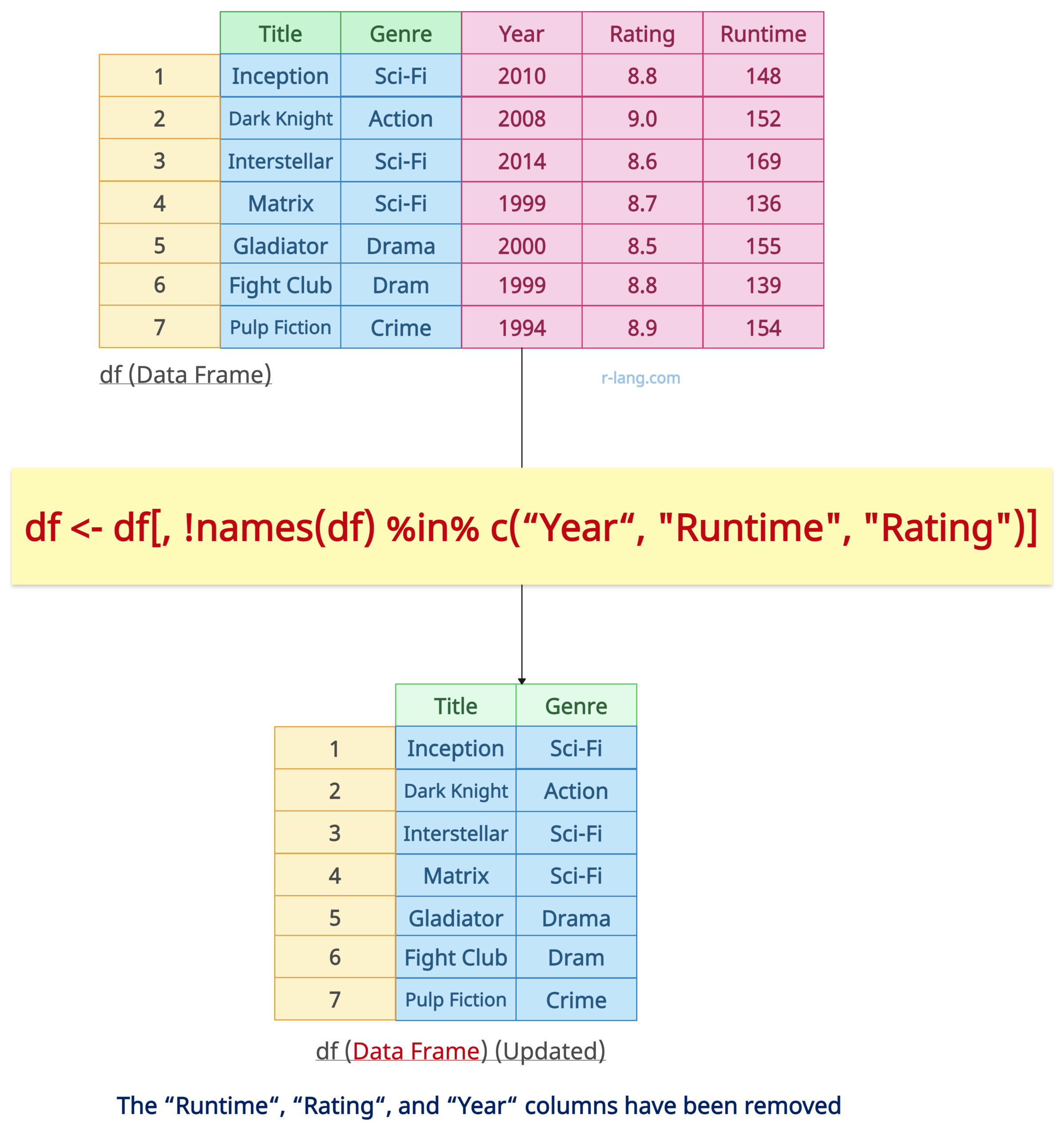
In this code, we removed three columns, “Year”, “Rating”, and “Runtime”, using subsetting.
Method 2: Using column indices
While subsetting, instead of passing column names, you can also pass column indices to remove them from a data frame.
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Subsetting using column indices
df <- df[, -c(3, 4, 5)]
print(df)
Output
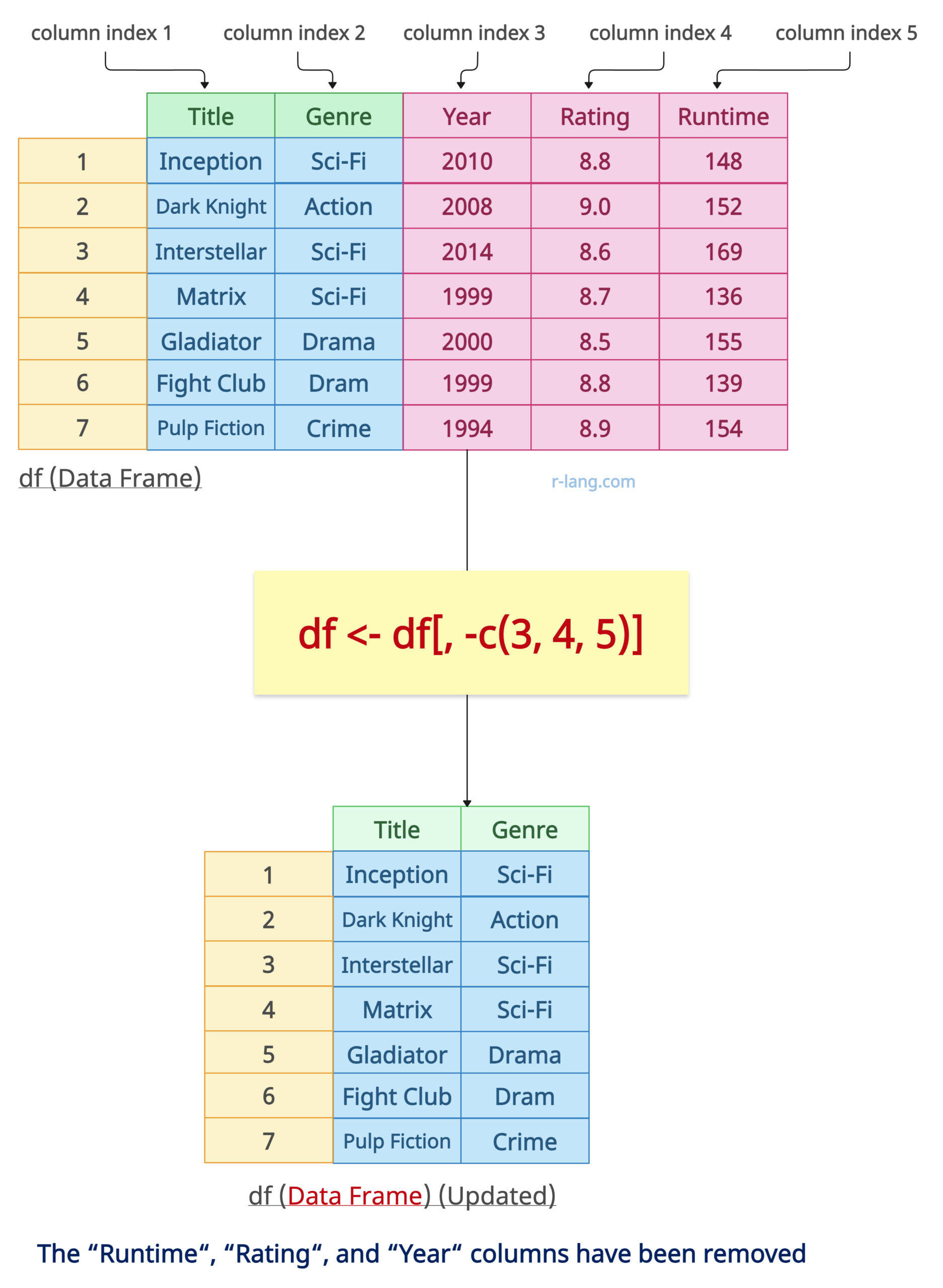
Method 3: Use within()
With the help of rm() and within() functions, you can remove multiple columns effortlessly. For example, within(df, rm(Rating, Runtime)) will remove two columns.
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Use within() to remove columns
df <- within(df, rm(Runtime, Rating))
print(df)
Output
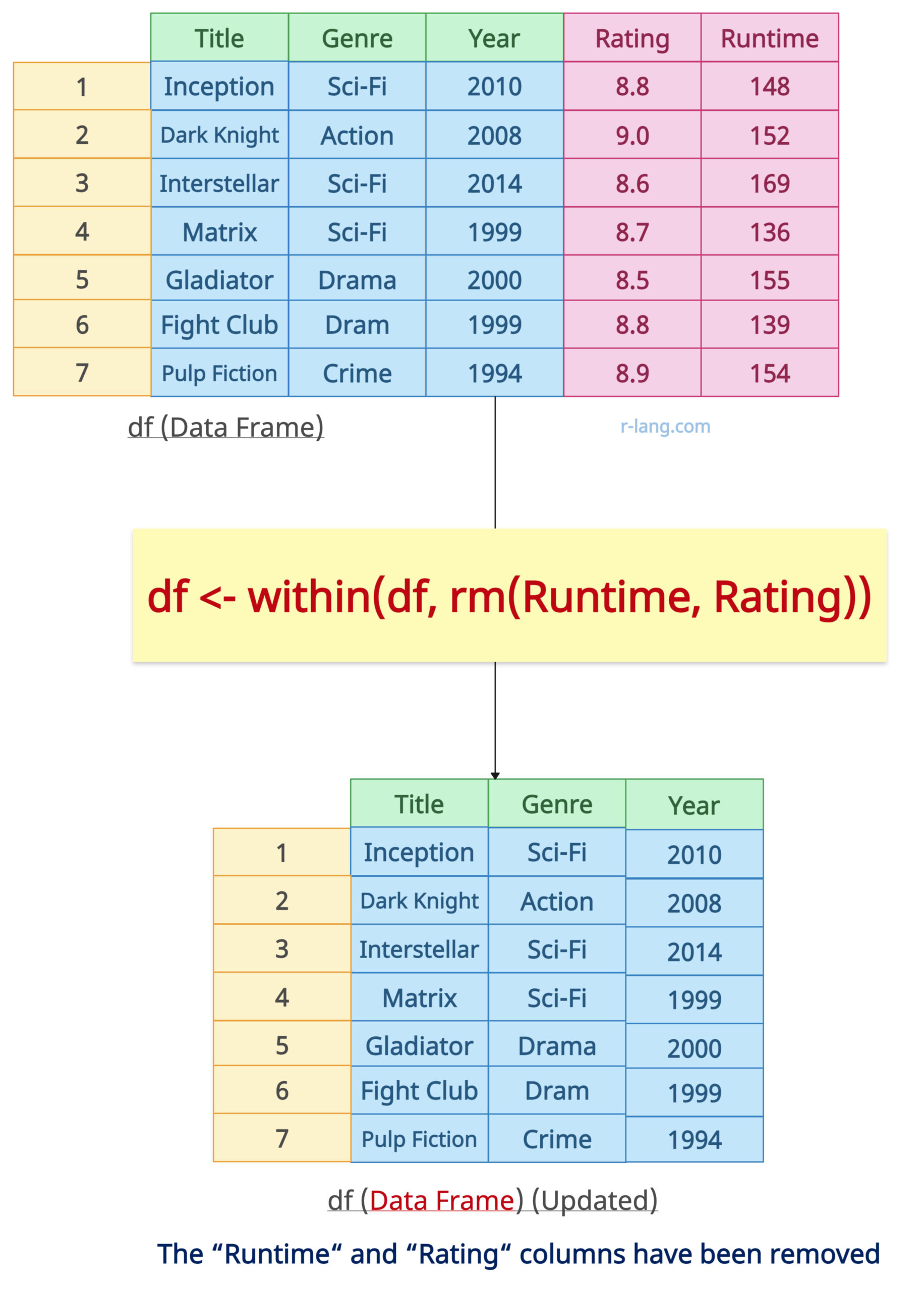
Method 4: Using dplyr::select
Using the dplyr::select() method, you can explicitly define the column names you want to remove from the data frame and prepend the hyphen (-) sign to each column.
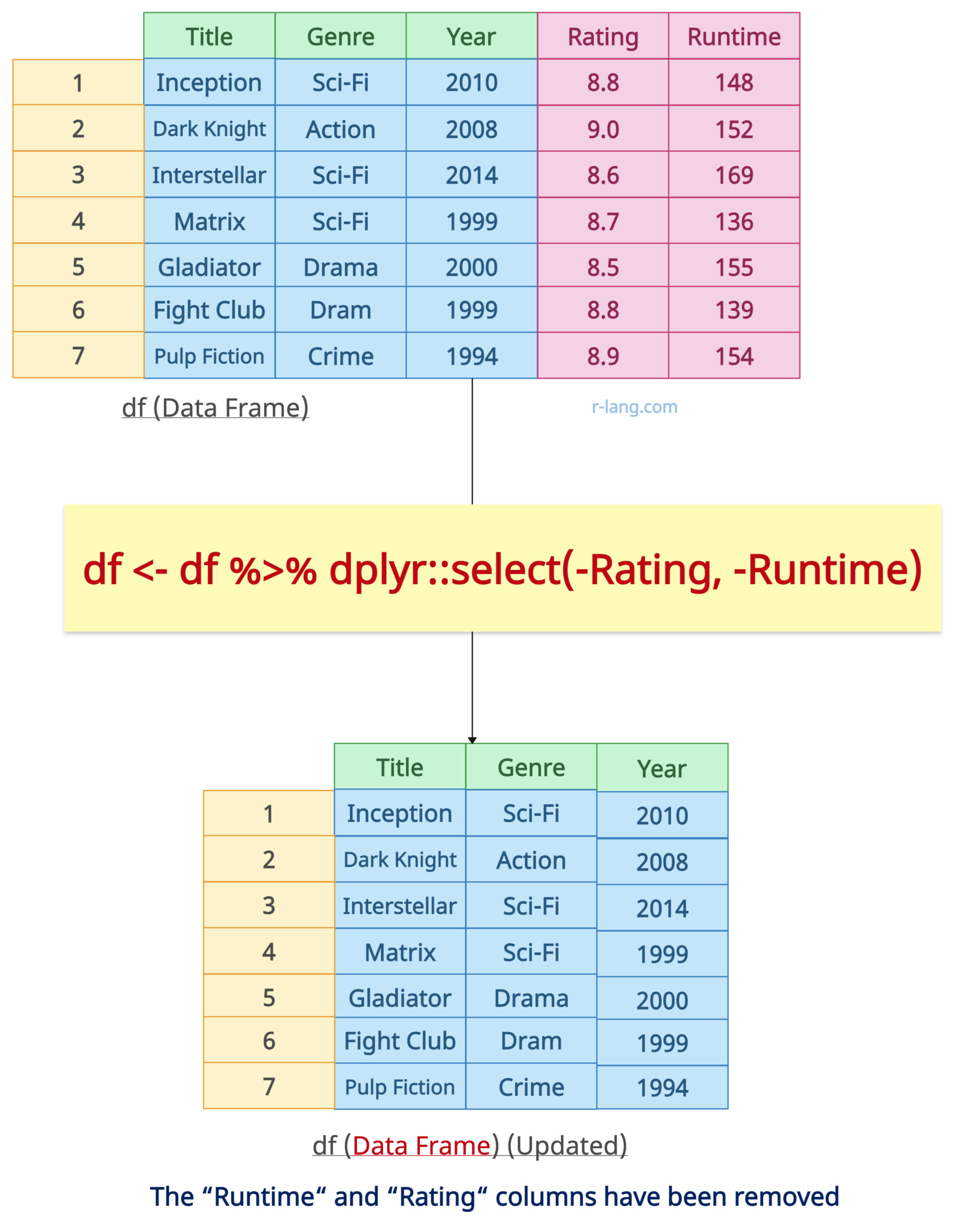
For example, df <- df %>% select(-Rating, -Runtime)
library(dplyr)
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Using dplyr to remove multiple columns
df <- df %>% select(-Runtime, -Rating)
print(df)
Output
Method 5: Deleting the range of columns
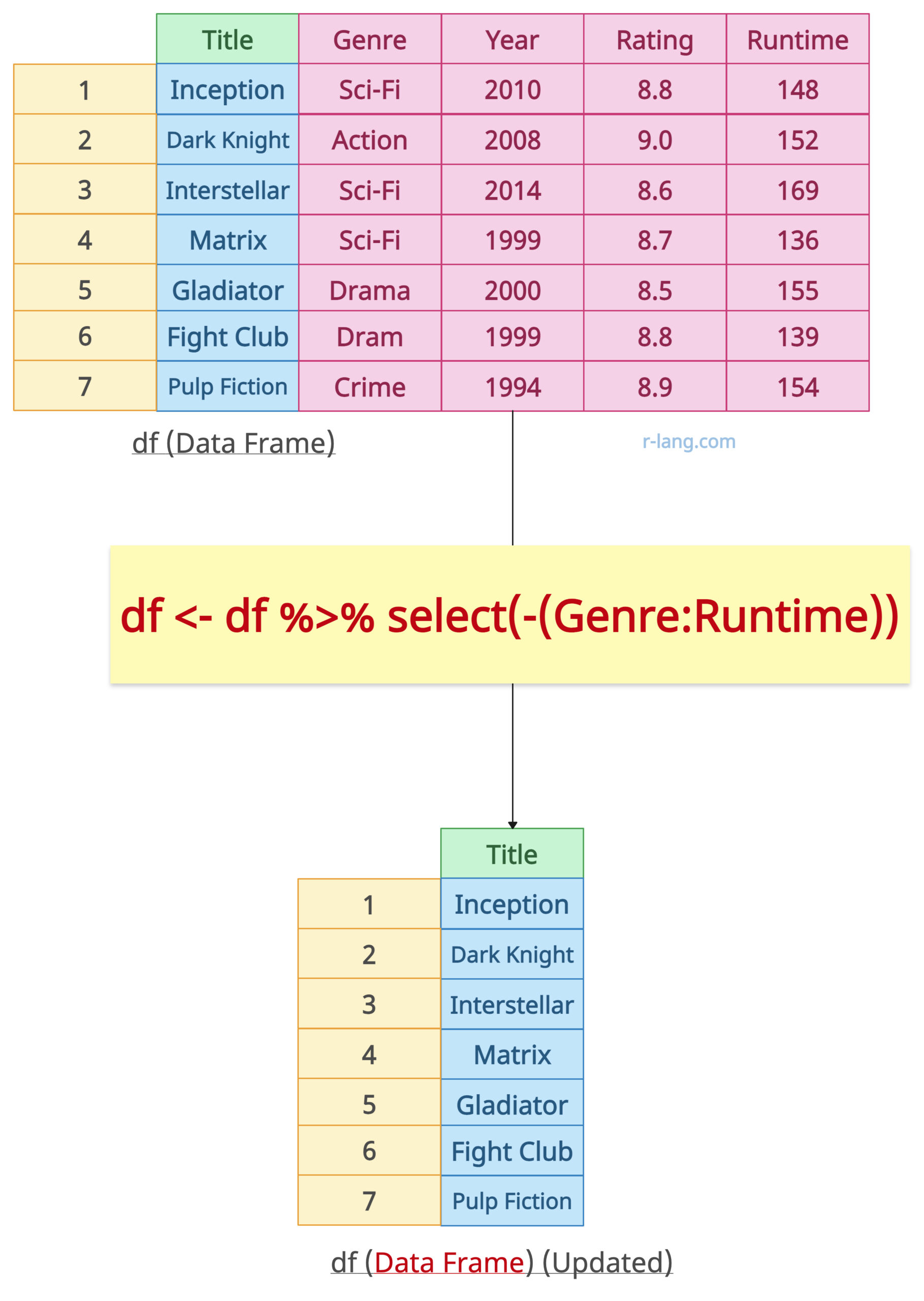
If you need to eliminate a range of columns from a data frame, you can use the syntax “select((column_start:column_end))”.
library(dplyr)
df <- data.frame(
Title = c(
"Inception", "The Dark Knight", "Interstellar", "The Matrix",
"Gladiator", "Fight Club", "Pulp Fiction"
),
Genre = c("Sci-Fi", "Action", "Sci-Fi", "Sci-Fi", "Drama", "Drama", "Crime"),
Year = c(2010, 2008, 2014, 1999, 2000, 1999, 1994),
Rating = c(8.8, 9.0, 8.6, 8.7, 8.5, 8.8, 8.9),
Runtime = c(148, 152, 169, 136, 155, 139, 154)
)
print(df)
# Delete a range of columns
df <- df %>% select(-(Genre:Runtime))
print(df)
Output
That’s all!

Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.