
Here are four different ways for different scenarios to remove NA values from a data frame:
- Use na.omit()
- Use complete.cases()
- Use is.na() with Subsetting
- Tidyverse approach
NA values are missing values. They are somehow absent from a data frame. Before creating a model based on a data frame, we need to clean the data frame of missing values, which depends on different scenarios.
Here is the sample data frame:
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", NA),
score = c(85, 90, 78, 92, 92, NA),
subject = c("Math", "Math", NA, "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", NA, NA)
)
print(df)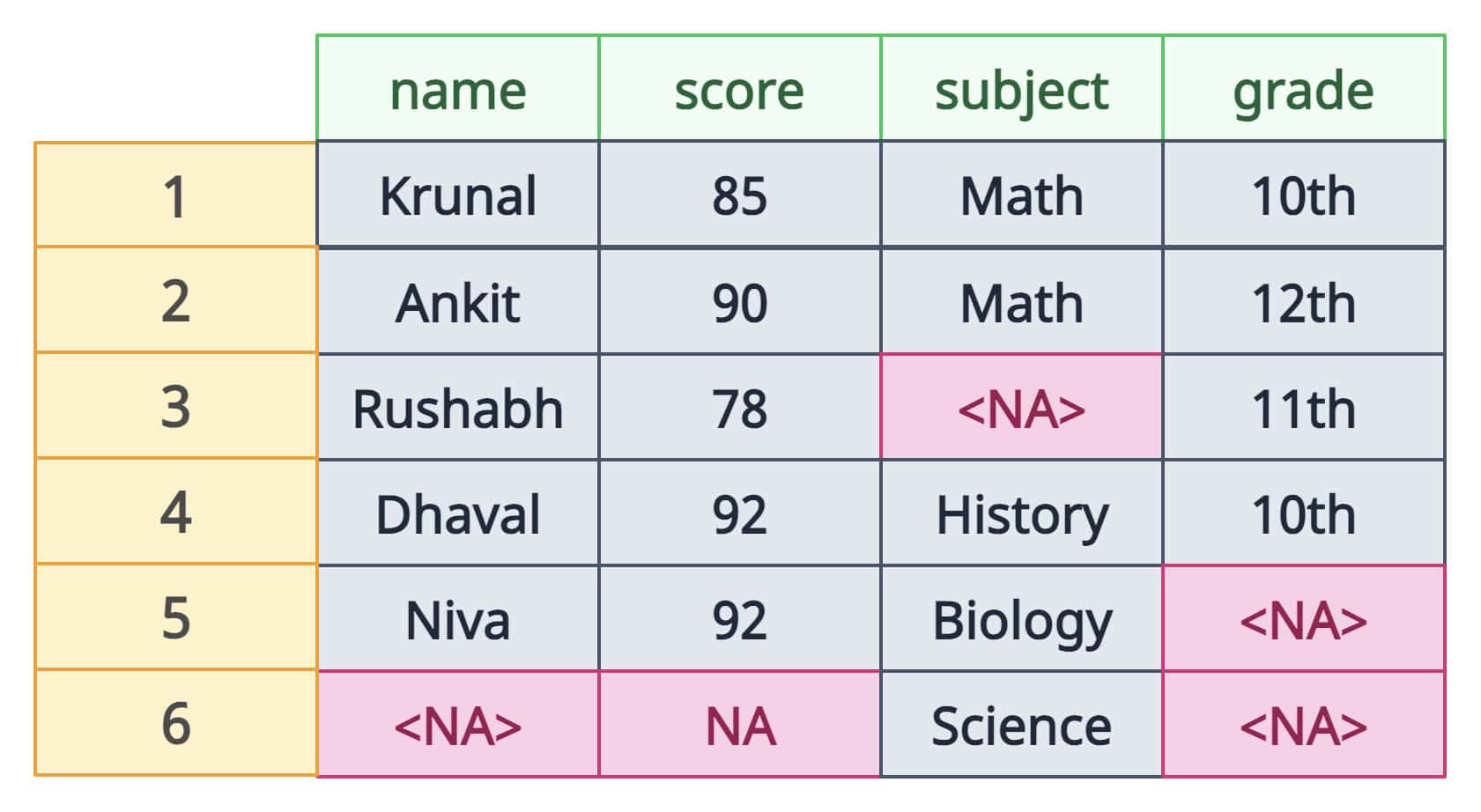
Method 1: Using na.omit()
The main operation of the na.omit() function is to remove all the rows containing any NA values from a data frame.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", NA),
score = c(85, 90, 78, 92, 92, NA),
subject = c("Math", "Math", NA, "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", NA, NA)
)
print(df)
# Removing rows with NA values
df_without_na <- na.omit(df)
print(df_without_na)Output

The above output figure shows that rows 3, 5, and 6 have been removed because they all contain at least one NA value.
Method 2: Using complete.cases()
The complete.cases() function provides flexibility: You can either remove all the rows that contain NA values or remove rows with NA in specific columns.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", NA),
score = c(85, 90, 78, 92, 92, NA),
subject = c("Math", "Math", NA, "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", NA, NA)
)
print(df)
# Removing rows with NA values
df_clean <- df[complete.cases(df), ]
print(df_clean)Output

You can use the complete.cases() on selected columns like this:
Let’s remove NAs based on columns “name” and “grade”.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", NA),
score = c(85, 90, 78, 92, 92, NA),
subject = c("Math", "Math", NA, "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", NA, NA)
)
print(df)
# Removing rows with NA values
df_clean_cols <- df[complete.cases(df[, c("name", "grade")]), ]
print(df_clean_cols)Output

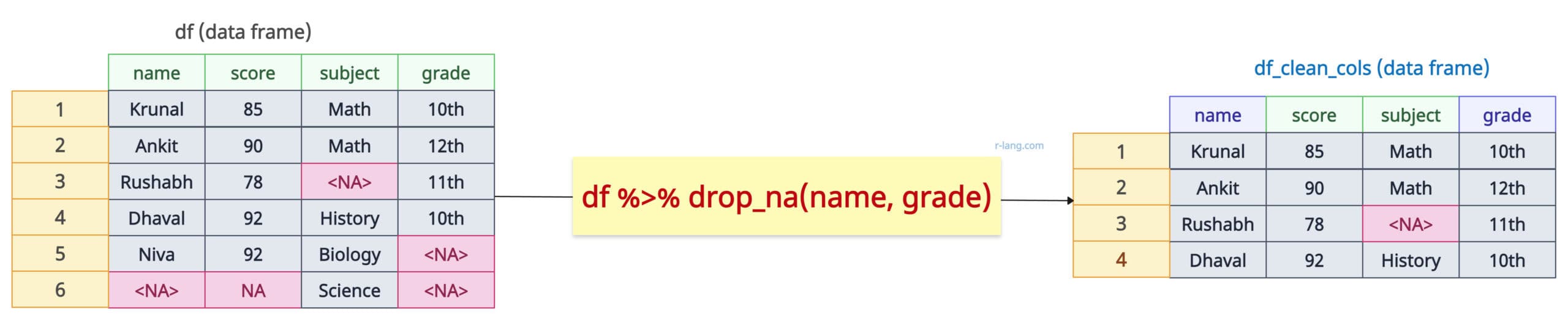
The “subject” column also has an NA value, but we did not specify that, so it is in the output.
Method 3: Use is.na() with Subsetting
Subsetting is a process where you apply specific conditions to a data frame and select the rows based on the outcome of those conditions. It is like selecting rows based on your filter.
You can subset rows where specific columns are not missing (i.e., not NA).
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", NA),
score = c(85, 90, 78, 92, 92, NA),
subject = c("Math", "Math", NA, "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", NA, NA)
)
print(df)
# Removing rows with NA values from column "name"
df_clean_name <- df[!is.na(df$name), ]
print(df_clean_name)Output

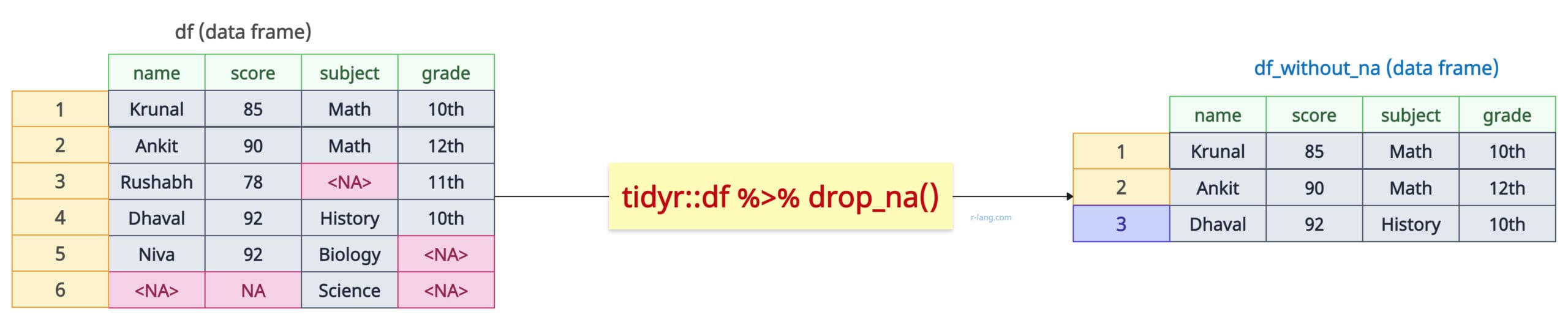
Method 4: Using tidyverse (dplyr/tidyr)
The tidyr::drop_na() function is designed to drop rows containing missing values.
Install the tidyr package and then load it using the library() function.
library(tidyr)
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", NA),
score = c(85, 90, 78, 92, 92, NA),
subject = c("Math", "Math", NA, "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", NA, NA)
)
print(df)
# Removing all rows with NA values
df_clean <- df %>% drop_na()
print(df_clean)Output
You can also remove rows with NA based on specific columns using the drop_na() function.
library(tidyr)
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", NA),
score = c(85, 90, 78, 92, 92, NA),
subject = c("Math", "Math", NA, "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", NA, NA)
)
print(df)
# Removing all rows with NA values
df_clean_cols <- df %>% drop_na(name, grade)
print(df_clean_cols)Output
That’s all!

Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.