The strsplit() function in R splits elements of a character vector into a list of substrings based on a specified delimiter or regular expression pattern.
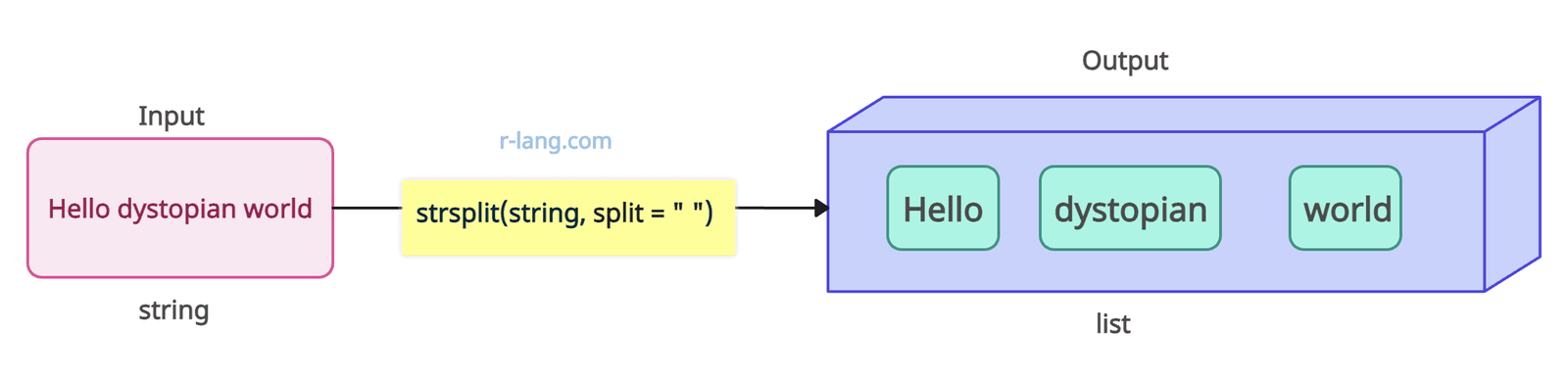
In the above figure, we are splitting a character vector “string” into three substrings based on the space in between them.
string <- ("Hello dystopian world")
strsplit(string, split = " ")
# Output:
# [[1]]
# [1] "Hello" "dystopian" "world"strsplit(x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE)
| Argument | Description |
| x | It is an input character vector that contains strings to be split. |
| split | It is a character vector or regular expression defining the delimiter from which you want to split a string. It can be a comma, a character, or anything your data has from which you want to split. If it is empty (“”), it splits into individual characters. |
| fixed | It is a logical argument, either TRUE or FALSE. The default is FALSE. As the name suggests, it is a fixed string rather than a regular expression. If TRUE, it will split a string based on a specific string, not a regular expression. Don’t use the “fixed” parameter if you are going to use a regular expression. |
| perl | It is a logical argument. The default is FALSE. It enables Perl-compatible regular expressions. |
| useBytes | It is a logical argument. The default is FALSE. If you set it to TRUE, it will split byte by byte rather than character by character. It allows byte-level splitting. |
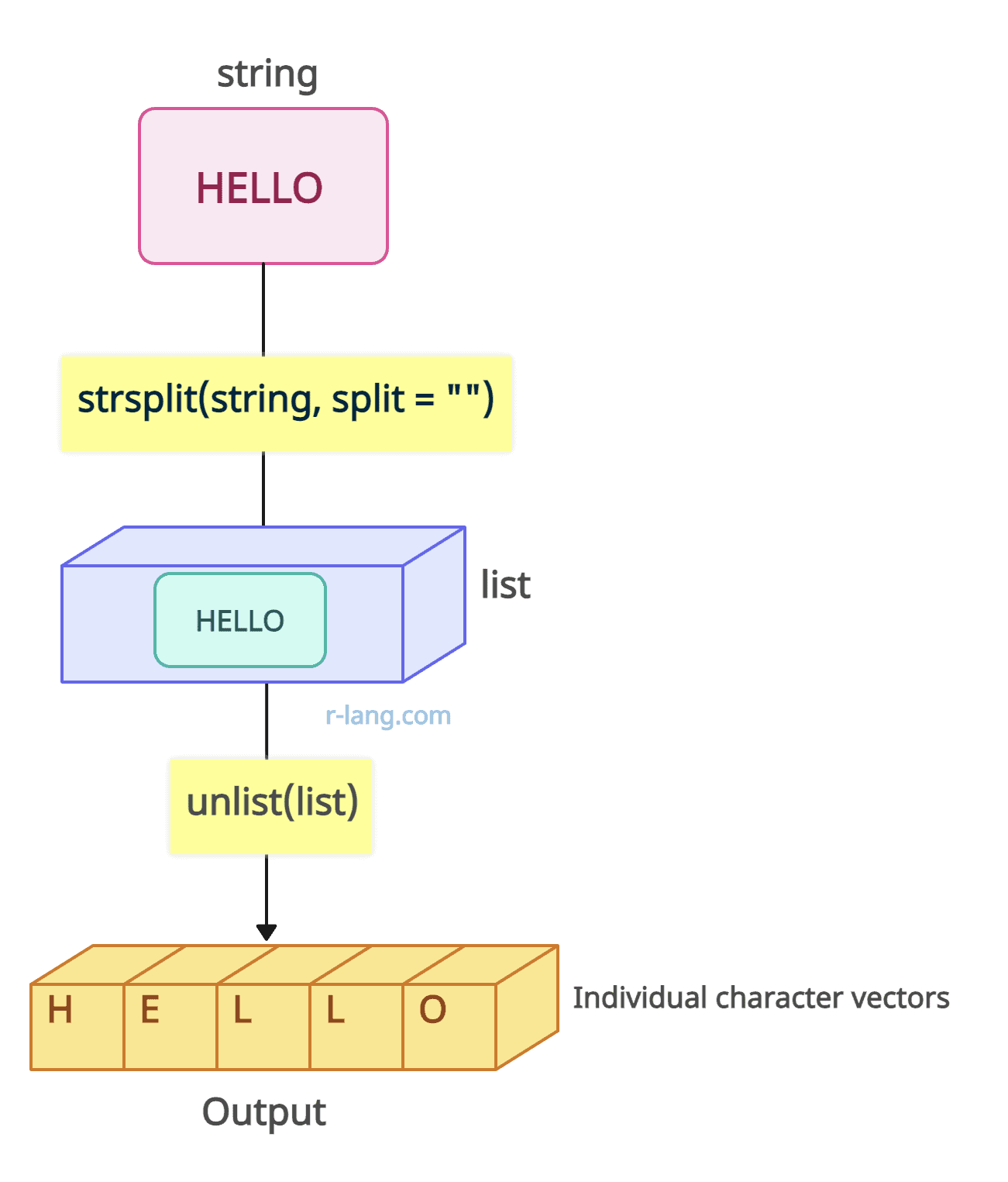
You can split a string into individual character vectors by passing an empty string as a delimiter, which will separate each character, and then use the unlist() function to convert the list into a vector.
string <- "hello"
list <- strsplit(string, split = "")
char_vector <- unlist(list)
print(char_vector)
# Output
# [1] "h" "e" "l" "l" "o"This function is not limited to a single string; you can use it to split the multiple strings.
# Multiple strings
strings <- c("one,two,three", "four,five,six")
# Split each string by ','
splitted <- strsplit(strings, split = ",")
# Print the result
print(splitted)
# Output:
# [[1]]
# [1] "one" "two" "three"
# [[2]]
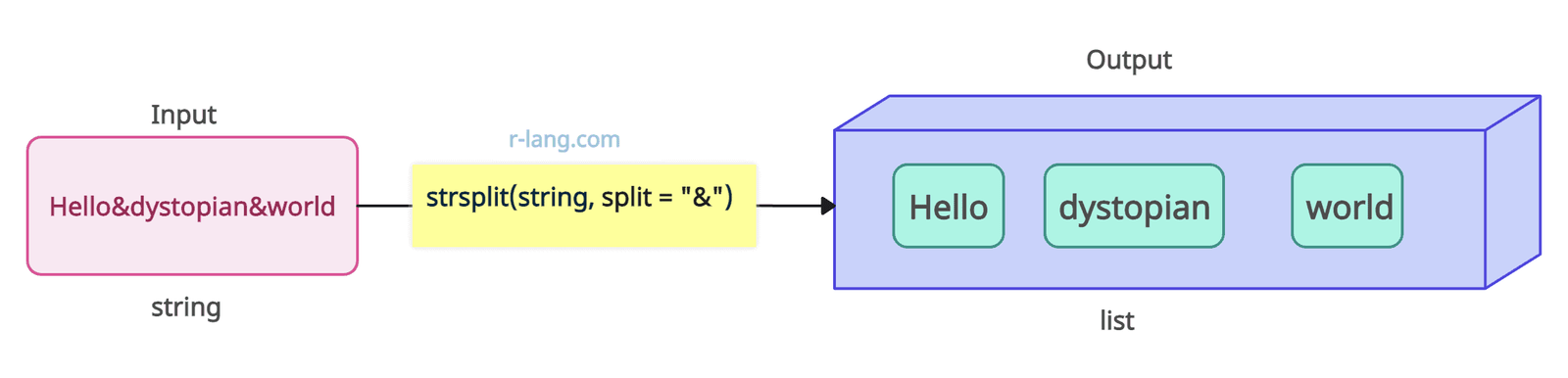
# [1] "four" "five" "six"You can pass a delimiter (a symbol or special character) that separates the words or text in the data.
The above figure illustrates how we split a string based on the “&” delimiter.
string <- "Hello&dystopian&world"
strsplit(string, split = "&")
# Output:
# [[1]]
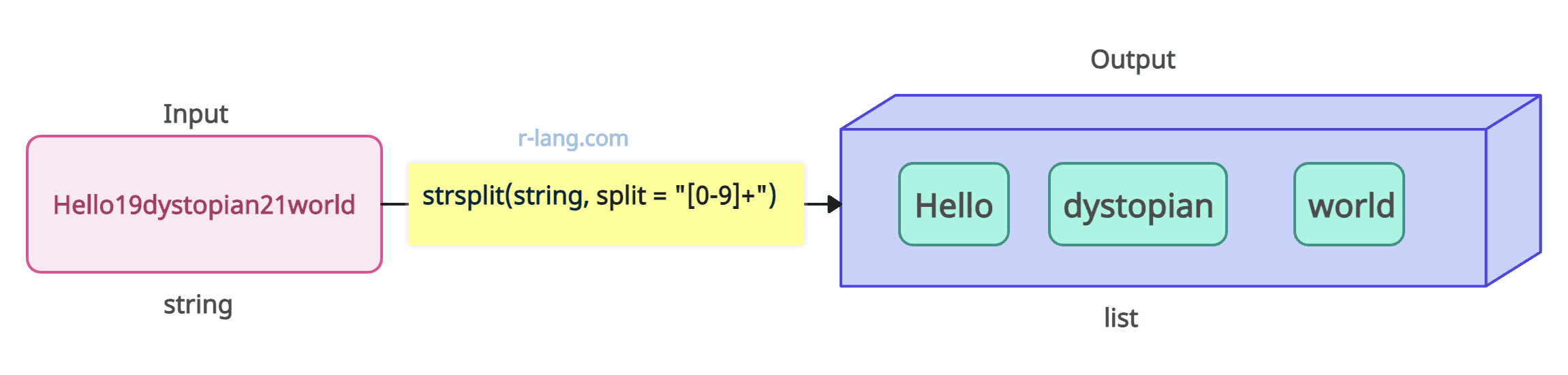
# [1] "Hello" "dystopian" "world"Regular expressions are a compact and flexible way of describing patterns in strings. You can provide the specific regular expression you need to split the string.
In the above figure, we split a string based on regular expression as a separator. Basically, we split a string where R found numerical values.
string <- ("Hello19dystpoian21world")
strsplit(string, split = "[0-9]+")
# Output:
# [[1]]
# [1] "Hello" "dystpoian" "world"If you set fixed = TRUE, it tells R to treat the split pattern as a fixed string, not as a regular expression.
fruits <- c("apple, banana, cherry", "orange, peach, grape")
split_fruits <- strsplit(fruits, ", ", fixed = TRUE)
print(split_fruits)
# Output
# [[1]]
# [1] "apple" "banana" "cherry"
# [[2]]
# [1] "orange" "peach" "grape"When it comes to NA values, the strsplit() function handles NA values gracefully.
When an input vector contains NA, this function includes NA in the output list at the corresponding position without causing errors or altering the structure of the result.
input_with_na <- c("data, info", NA, "red,blue")
output_including_na <- strsplit(input_with_na, ",")
print(output_including_na)
# Output:
# [[1]]
# [1] "data" " info"
# [[2]]
# [1] NA
# [[3]]
# [1] "red" "blue"
If you want to use a Perl-compatible regular expression, you can do it by passing perl=TRUE in the argument.
complex_string <- "audi123bmw456bugatti"
perl_pattern_output <- strsplit(complex_string, "\\d+", perl = TRUE)
print(perl_pattern_output)
# Output
# [[1]]
# [1] "audi" "bmw" "bugatti"In this code, the Perl-compatible regex \\d+ matches one or more digits, splitting the string at numeric sequences.
For non-standard encodings, you might have to split the string at the byte level.
non_standard_string <- "café"
# Splitting the string byte-by-byte
byte_split <- strsplit(non_standard_string, "", useBytes = TRUE)
print(byte_split)
# Output
# [[1]]
# [1] "c" "a" "f" "\xc3" "\xa9"On most UTF-8 systems, the output looks like above program. It helps manage non-UTF-8 encodings.
That’s all!
Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.
The scale() function in R centers (subtracting the mean) and/or scales (dividing by the standard…
To rename a file in R, you can use the file.rename() function. It renames a…
The prop.table() function in R calculates the proportion or relative frequency of values in a…
The exp() is a built-in function that calculates the exponential of its input, raising Euler's…
The split() function divides the input data into groups based on some criteria, typically specified…
The colMeans() function in R calculates the arithmetic mean of columns in a numeric matrix,…
{kind=link}
{kind=link}
{kind=link}
{kind=link}