Here are three major ways to remove the last row from the data frame in R:
We have already seen how to remove the first row and its use cases.
To determine the total number of rows, we can use the built-in nrow() function, and using negative indexing, we can exclude the last row from the data frame. If we turn our logic into code, it looks like this: df[-nrow(df), ].
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", "Mansi"),
score = c(85, 90, 78, 92, 92, 88),
subject = c("Math", "Math", "History", "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", "12th", "10th")
)
df # Printing df before removing the last row
df <- df[-nrow(df), ]
df
# Printing df after removing the last rowOutput
The nrow() returns a total number of rows, which is 6 in our case. Then, we subtract -1 from 6, which is 5. So, we subset the first five rows. The above figure shows that row number 6 has been removed.
To remove the last N rows, we have to modify our previous logic because N can be any number of rows.
Let’s say N = 3, which means we need to remove the last three rows. How are we going to do that?
First, we can use the nrow() function to get the total number of rows and then create a sequence from the (N-th last row) to the last row. Use negative indexing (-) before this sequence to exclude those rows.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", "Mansi"),
score = c(85, 90, 78, 92, 92, 88),
subject = c("Math", "Math", "History", "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", "12th", "10th")
)
df # Before removing the last N rows
# Specify number of rows to remove
N <- 3
# Remove the last N rows
df <- df[-((nrow(df) - N + 1):nrow(df)), ]
df
# After removing the last N = 3 rowsOutput
If we have a data frame that contains only a single row, then after removing the last row (which means that a single row), it will return an empty data frame without giving any errors.
df <- data.frame(
name = c("Krunal"),
score = c(85),
subject = c("Math"),
grade = c("10th")
)
df # Printing before moving the last (only) row
df <- df[-nrow(df), ]
df
#Printing after moving the last (only) rowOutput
If you provide an empty data frame, it will still return an empty data frame without any error.
df <- data.frame(
name = c(),
score = c(),
subject = c(),
grade = c()
)
df # data frame with 0 columns and 0 rows
df <- df[-nrow(df), ]
df
# data frame with 0 columns and 0 rowsOutput
The above approaches are still unsafe even if they don’t throw any errors. We can enhance our approach by checking if our data frame has at least 2 rows, and then removing the last row. That way, at least one row will be there in the final data frame to avoid any future potential issues.
df_with_one_row <- data.frame(
name = c("Krunal"),
score = c(85),
subject = c("Math"),
grade = c("10th")
)
df_empty <- data.frame(
name = c(),
score = c(),
subject = c(),
grade = c()
)
# Function to safely remove the last row
remove_last_row <- function(df) {
if (nrow(df) > 1) {
df <- df[-nrow(df), ]
} else {
message("DataFrame is empty or has only one row. Returning original DataFrame.")
}
return(df)
}
# Test the function
df_empty <- remove_last_row(df_empty)
df_one_row <- remove_last_row(df_with_one_row)
# Output: DataFrame is empty or has only one row. Returning original DataFrame.
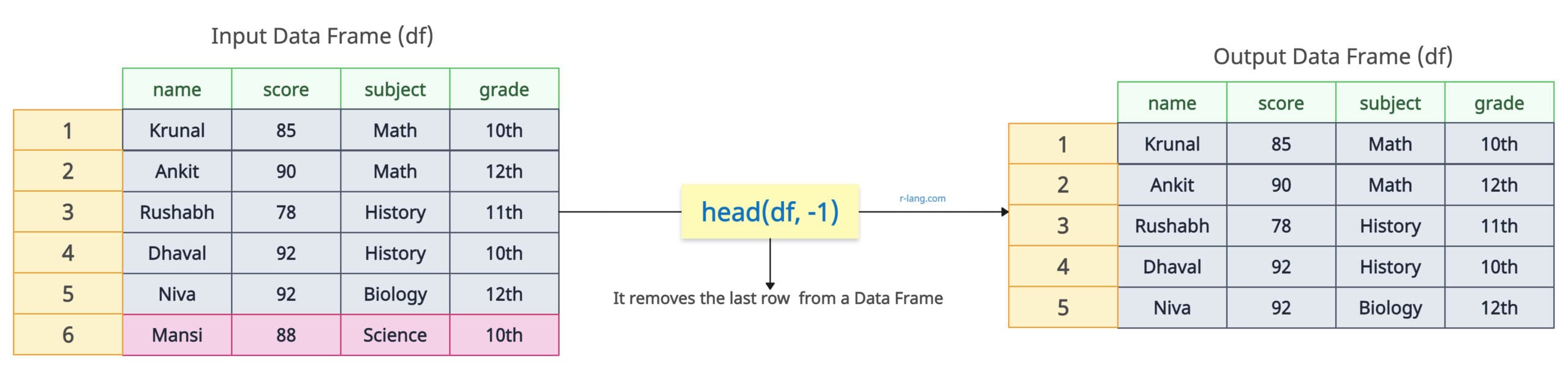
# Output: DataFrame is empty or has only one row. Returning original DataFrame.By default, the head() function returns the first six rows unless you pass the n parameter, which tells you the number of rows. If you pass n=-1, it will exclude the last row and return the remaining rows.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", "Mansi"),
score = c(85, 90, 78, 92, 92, 88),
subject = c("Math", "Math", "History", "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", "12th", "10th")
)
df # Print the data frame
head(df, -1)
# Print the data frame without the last rowOutput
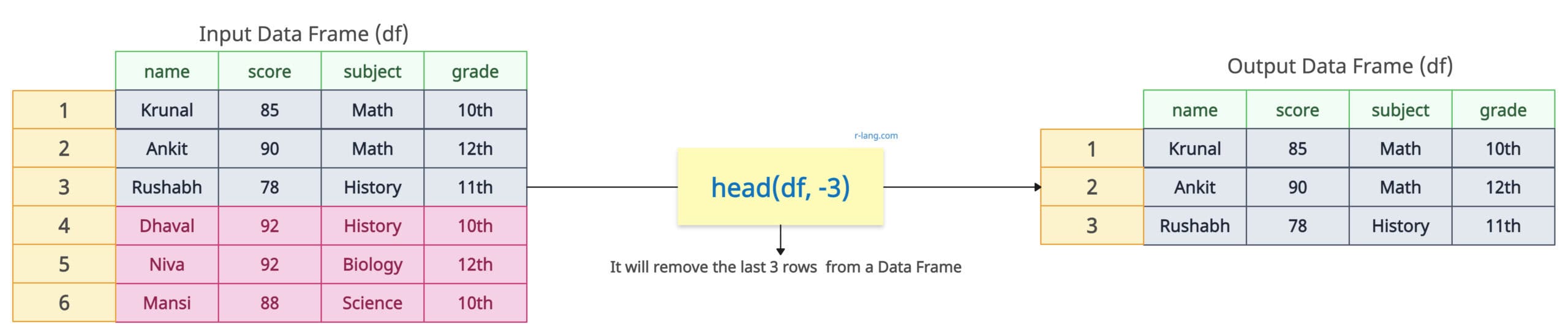
For example, if I want to remove the last three rows, I will pass -3 as the second argument. Like this: head(df, -3).
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", "Mansi"),
score = c(85, 90, 78, 92, 92, 88),
subject = c("Math", "Math", "History", "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", "12th", "10th")
)
df # Print the data frame
df <- head(df, -3) # Minus will exclude the rows. Removing last 3 rows.
df
# Print the updated data frameOutput
If you have a data frame with only one row and you try to remove that row, it will return an empty data frame without giving you an error.
If you operate head() on an empty data frame, it will still return an empty data frame.
The dplyr package provides a slice() method for selecting rows based on position. It allows positive values (to include specific rows) or negative values (to exclude specific rows).
Install and load the dplyr package.
library(dplyr)
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", "Mansi"),
score = c(85, 90, 78, 92, 92, 88),
subject = c("Math", "Math", "History", "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", "12th", "10th")
)
df
# Print the data frame
df %>% slice(-nrow(.))Output
To remove the last N rows using the dplyr package, use the nrow(.) dynamically calculates the number of rows. Then, we will create a sequence from the (N-th last row) to the last row and exclude them using negative indexing. Finally, pass everything to the slice() method.
# Load dplyr package
library(dplyr)
# Sample DataFrame
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Niva", "Mansi"),
score = c(85, 90, 78, 92, 92, 88),
subject = c("Math", "Math", "History", "History", "Biology", "Science"),
grade = c("10th", "12th", "11th", "10th", "12th", "10th")
)
# Print the original DataFrame
df
# Specify the number of rows to remove
N <- 3
# Remove the last N rows
df <- df %>% slice(-((nrow(.) - N + 1):nrow(.)))
# Print the updated DataFrame
dfOutput
If your data frame is empty or has only a single row and you try to remove the last row, it will return an empty data frame without giving you an error.
That’s it!
Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.
The scale() function in R centers (subtracting the mean) and/or scales (dividing by the standard…
To rename a file in R, you can use the file.rename() function. It renames a…
The prop.table() function in R calculates the proportion or relative frequency of values in a…
The exp() is a built-in function that calculates the exponential of its input, raising Euler's…
The split() function divides the input data into groups based on some criteria, typically specified…
The colMeans() function in R calculates the arithmetic mean of columns in a numeric matrix,…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}