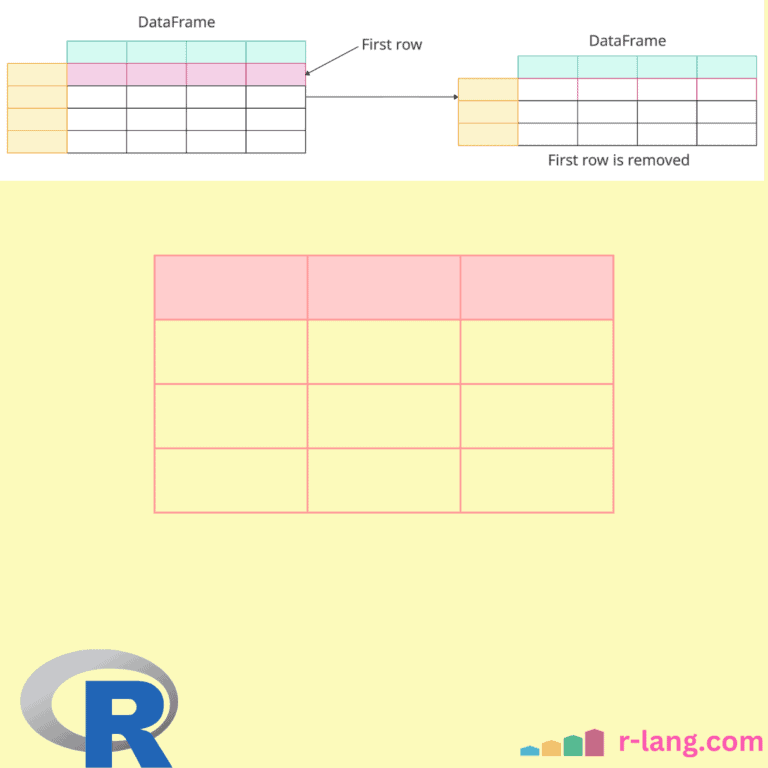
Here are three ways to remove the first row of a data frame in R:
- Using negative indexing
- Using dplyr::slice()
- Using tail()
Method 1: Using negative indexing
Negative indexing is a method for excluding specific rows based on your requirements. Since we need to remove the first row, we can use df[-1, ], where -1 indicates that we should exclude the first row.
df <- data.frame(
age = c(20, 21, 19, 22, 21),
gender = c("Male", "Female", "Male", "Female", "Male"),
score = c(85, 90, 88, 78, 92)
)
df[-1, ]
Output

The above output screenshot shows that the first row with row index 1 is removed from the data frame. We are removing a row by its position.
It’s important to note that the row indices have not been reset, meaning that the row index starts at 2 instead of 1.
Data Frame with One Row
When you have a data frame containing only one row, df[-1, ] will return an empty data frame. It won’t throw any error.
If you don’t use drop = FALSE, the result might inadvertently convert to a vector (although with 0 rows, it remains a DataFrame).
df <- data.frame(
age = c(20),
gender = c("Male"),
score = c(85)
)
df[-1, , drop = FALSE]
# [1] age gender score
# <0 rows> (or 0-length row.names)
Empty Data Frame
If the data frame is already empty and you try to remove the first row, it will still return an empty data frame.
df <- data.frame()
df[-1, , drop = FALSE]
# data frame with 0 columns and 0 rowsChecking row count before removal
Sometimes, you have an empty data frame and try to remove rows, which results in an expected error. We can prevent this by checking if it contains any rows before removal.
Use nrow() to avoid unintended empty results. Let’s create a reusable function to handle edge cases.
df <- data.frame()
safe_remove_first_row <- function(df) {
if (nrow(df) == 0) {
return(df)
}
df[-1, , drop = FALSE]
}
safe_remove_first_row(df)
# data frame with 0 columns and 0 rowsMethod 2: Using dplyr::slice()
The dplyr slice() function selects rows from a data frame, and using slice(df, -1), we can remove the first row. However, you must ensure that dplyr is installed and loaded in your environment.
library(dplyr)
df <- data.frame(
age = c(20, 21, 19, 22, 21),
gender = c("Male", "Female", "Male", "Female", "Male"),
score = c(85, 90, 88, 78, 92)
)
df <- df %>% slice(-1)
df
Output

After removing the first row, you’ll notice that the row index has been reset, starting again at 1.
If the data frame has only one row and you remove that row, it will return an empty data frame. Unlike base R, it always preserves the DataFrame structure.
library(dplyr)
df <- data.frame(
age = c(20),
gender = c("Male"),
score = c(85)
)
df <- df %>% slice(-1)
df
# data frame with 0 columns and 0 rowsIf your data frame is empty and you use the slice(-1) method, it will still return an empty data frame and will not give any error.
library(dplyr)
df <- data.frame()
df <- df %>% slice(-1)
df
# data frame with 0 columns and 0 rowsMethod 3: Using tail()
The base tail() function returns the last five rows of the data frame, but if you use a tail() function with n = -1, it excludes the first row.
df <- data.frame(
age = c(20, 21, 19, 22, 21),
gender = c("Male", "Female", "Male", "Female", "Male"),
score = c(85, 90, 88, 78, 92)
)
df <- tail(df, n = -1)
df
Output
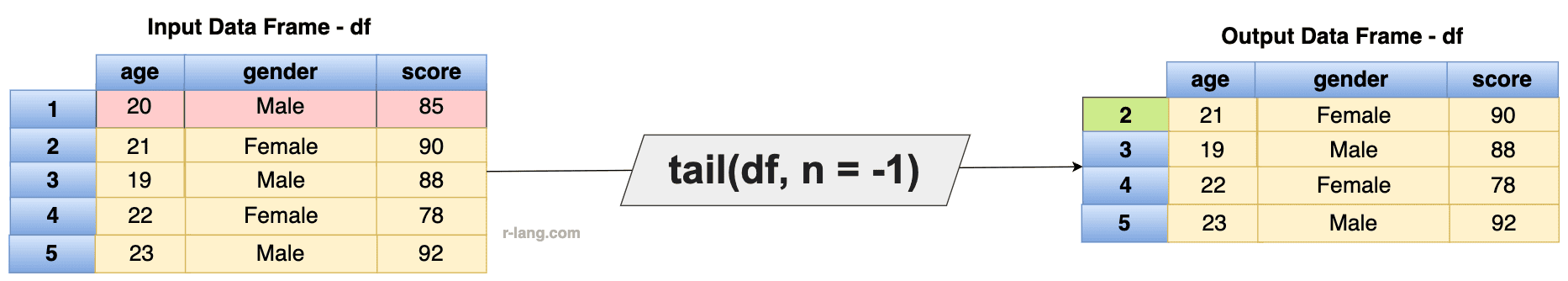
The above output screenshot shows that after the removal, the row index does not reset. It starts from row 2.
If the data frame has a single row, it will return an empty data frame.
df <- data.frame(
age = c(20),
gender = c("Male"),
score = c(85)
)
df <- tail(df, n = -1)
df
# <0 rows> (or 0-length row.names) If the data frame is already empty, it will return an empty data frame without any errors.
df <- data.frame()
df <- tail(df, n = -1)
df
# data frame with 0 columns and 0 rowsThat’s it!

Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.