The split() function divides the input data into groups based on some criteria, typically specified by one or more grouping factors.
The split() function always returns a list, with elements named after the levels of the factor and does not modify the original data.
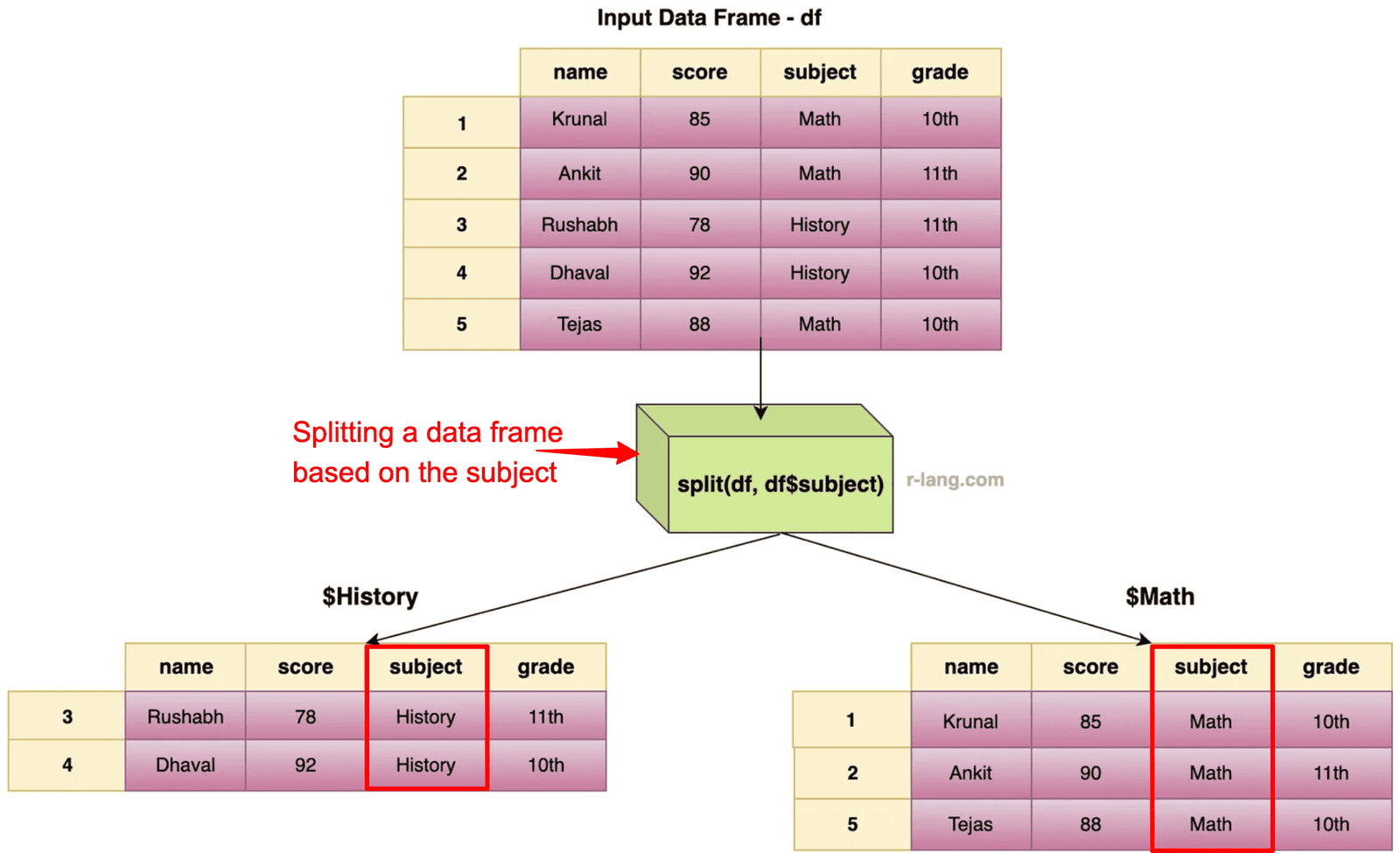
In the above figure, we split the data frame by the subject column. That means we are dividing the data based on the subject values.
If there are two unique subjects, the data frame will be divided into two sub-data frames. If you have performed database operations, it is similar to how the GROUP BY clause works.
The output is a list with two groups.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Tejas"),
score = c(85, 90, 78, 92, 88),
subject = c("Math", "Math", "History", "History", "Math"),
grade = c("10th", "11th", "11th", "10th", "10th")
)
# Split the data frame by subject
split_df <- split(df, df$subject)
# Print the split data frame
print(split_df)
# Output:
# $History
# name score subject grade
# 3 Rushabh 78 History 11th
# 4 Dhaval 92 History 10th
# $Math
# name score subject grade
# 1 Krunal 85 Math 10th
# 2 Ankit 90 Math 11th
# 5 Tejas 88 Math 10thYou can use the unsplit() function to restore the original data frame: unsplit(df, f = df$subject)
split(data, factor, drop = FALSE, sep = ".", lex.order = FALSE)| Argument | Description |
| data | It represents either a data frame or a vector that is divided into groups. For data frames, splitting occurs row-wise. |
| factor | It represents a factor or a list of factors defining groups. |
| drop (default: FALSE) | It is a logical argument, and if set to TRUE, empty levels in factors are dropped. |
| sep | It represents the Character string (default: “.”). |
| lex.order | If set to TRUE, group names are sorted in lexicographic order when factor is a list. |
You can split a vector into two vectors where elements are of the same group, passing the names of the vector with the names function to the f argument.
In the above figure, we split the vector based on its name.
So, the list has two values $x and $y and each contains its respective values.
vec <- c(x = 3, y = 5, x = 1, x = 4)
vec
# Output:
# x y x x
# 3 5 1 4
data <- split(vec, f = names(vec))
data
# Output:
# $x
# x x
# 3 1
# $y
# y y
# 5 4If you split a list, it will return multiple sub-lists based on the groupings.
main_list <- list(a = 1:2, b = 3:4)
split(main_list, c("g1", "g2"))
# Output:
# $g1
# $g1$a
# [1] 1 2
# $g2
# $g2$b
# [1] 3 4You can also split the built-in dataset into multiple groups based on the specified column values.
data("ToothGrowth")
df <- head(ToothGrowth)
data <- split(df, f = df$len)
dataOutput
$`4.2`
len supp dose
1 4.2 VC 0.5
$`5.8`
len supp dose
4 5.8 VC 0.5
$`6.4`
len supp dose
5 6.4 VC 0.5
$`7.3`
len supp dose
3 7.3 VC 0.5
$`10`
len supp dose
6 10 VC 0.5
$`11.5`
len supp dose
2 11.5 VC 0.5Let’s say we have a vector with only two values, but the factor we defined for splitting has three values. That means one factor value will be unused.
By using drop = TRUE, we will drop that third factor value because of its uselessness.
f <- factor(c("A", "B"), levels = c("A", "B", "C"))
split(1:2, f, drop = TRUE)
# Output:
# $A
# [1] 1
# $B
# [1] 2
The above output suggests that level “C” is dropped and only two values are splitted, one with group $A and one with group $B.
If the vector is empty and the factor is also empty, the output list will be empty too, since there is nothing to divide.
# Splitting empty objects
input_empty <- numeric(0)
factor_empty <- factor(character(0))
empty_list <- split(input_empty, factor_empty)
print(empty_list)
# Output: named list()That’s it.
Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.
The scale() function in R centers (subtracting the mean) and/or scales (dividing by the standard…
To rename a file in R, you can use the file.rename() function. It renames a…
The prop.table() function in R calculates the proportion or relative frequency of values in a…
The exp() is a built-in function that calculates the exponential of its input, raising Euler's…
The colMeans() function in R calculates the arithmetic mean of columns in a numeric matrix,…
The rowMeans() is a built-in, highly vectorized function in R that computes the arithmetic mean…
{kind=link}
{kind=link}