The dplyr filter() function in R subsets a data frame and retains all rows that satisfy the conditions. In other words, you can select the data frame rows based on conditions.
To retain rows, they should produce the output to TRUE, and if they return NA, they will be dropped from the data frame.
filter(.df, ..., .by = NULL, .preserve = FALSE)| Name | Value |
| .df | It is an input data frame or tibble. |
| … | These are logical conditions for filtering rows. You can combine multiple conditions with the &(AND) operator. |
| .by (Optional) | Grouping specification (alternative to group_by()). |
| .preserve (Optional) | If TRUE, preserves grouping structure (relevant for grouped data). |
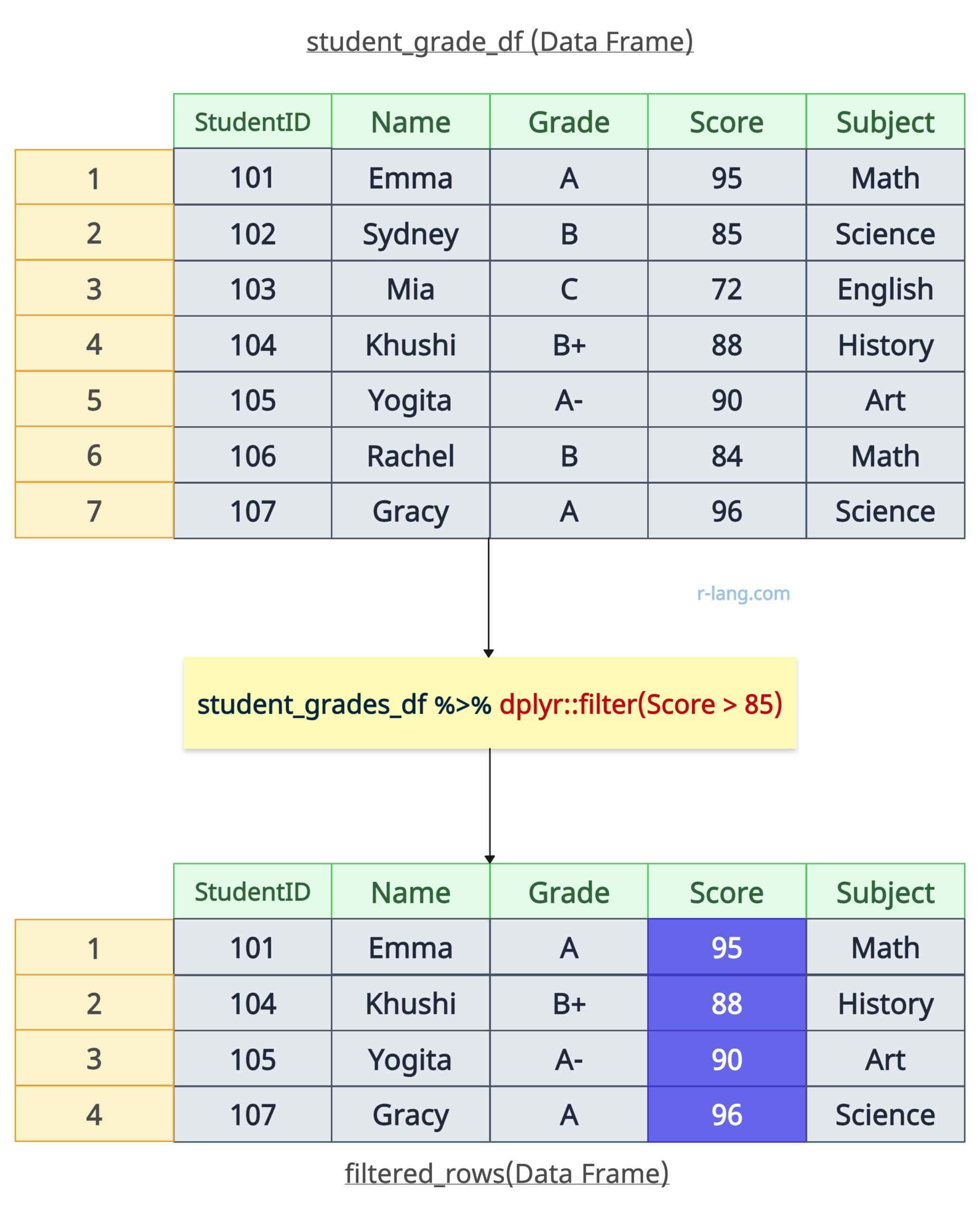
Here is the sample data frame we will use for this tutorial:
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
print(student_grades_df)Also, install the dplyr library if you have not already and load it in your file at the head of the code:
library(dplyr)Let’s create a basic filter that selects the rows with student scores greater than 85.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
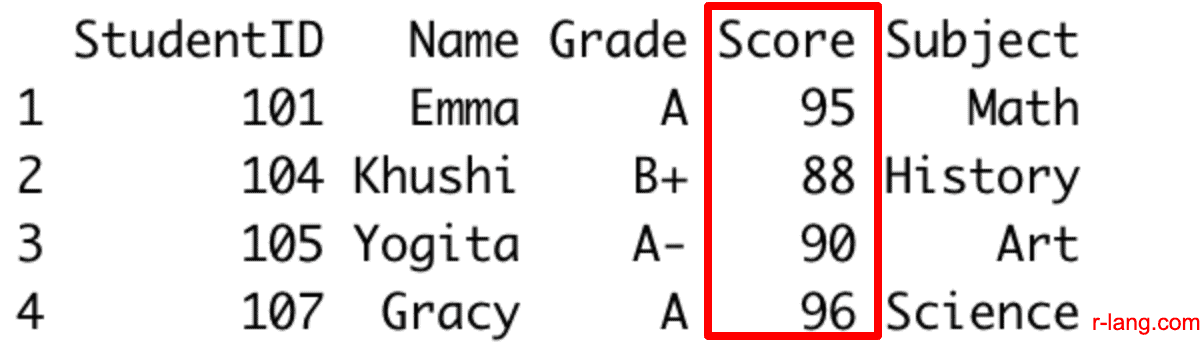
filtered_rows <- student_grades_df %>% filter(Score > 85)
print(filtered_rows)
Output
If you have multiple conditions, you can use the logical AND (&) / OR (|) operator to club them.
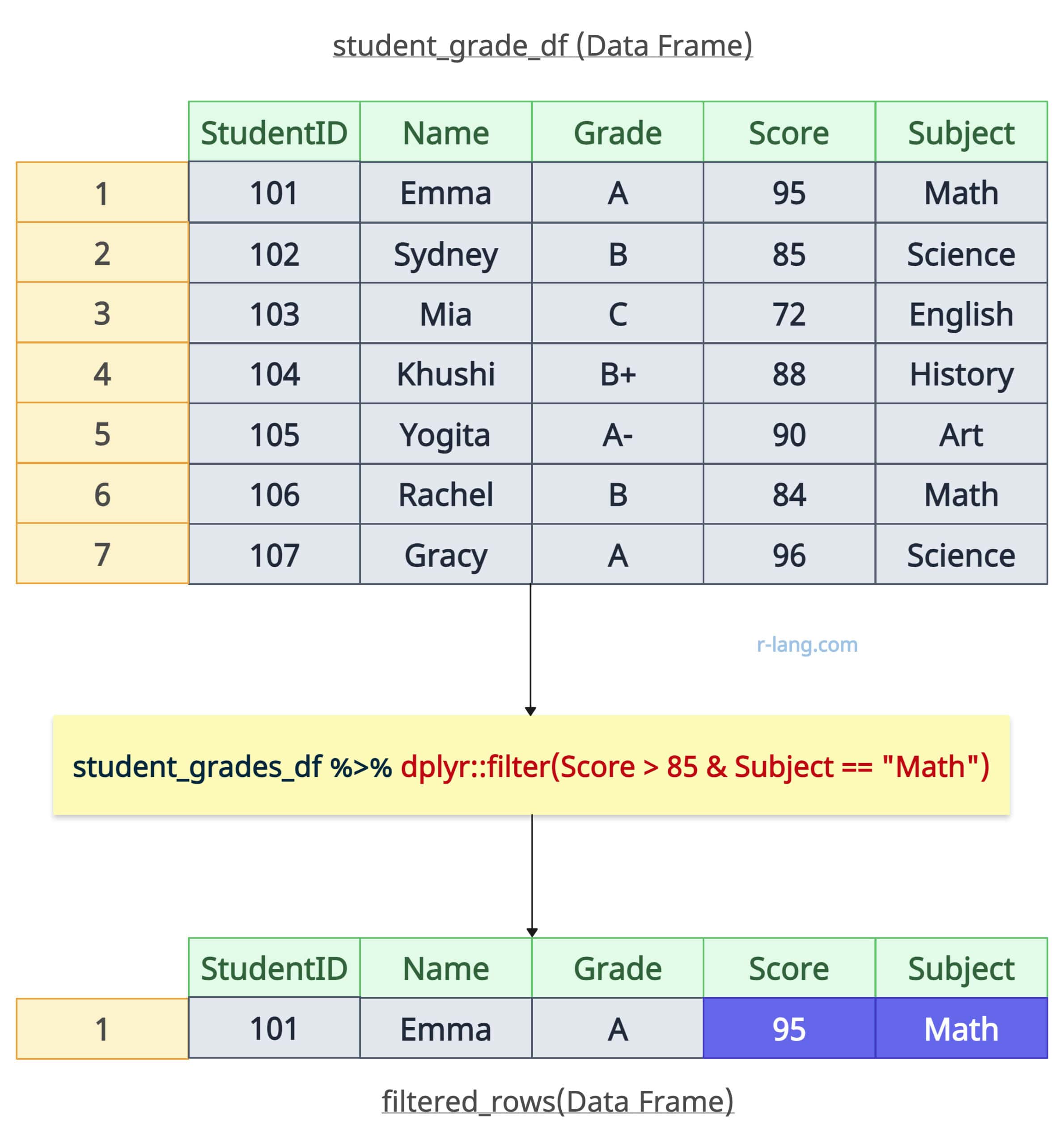
What if we want to get data with scores greater than 85, and the subject is Math? Let’s implement these conditions using the & operator.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
# Multiple Conditions (AND)
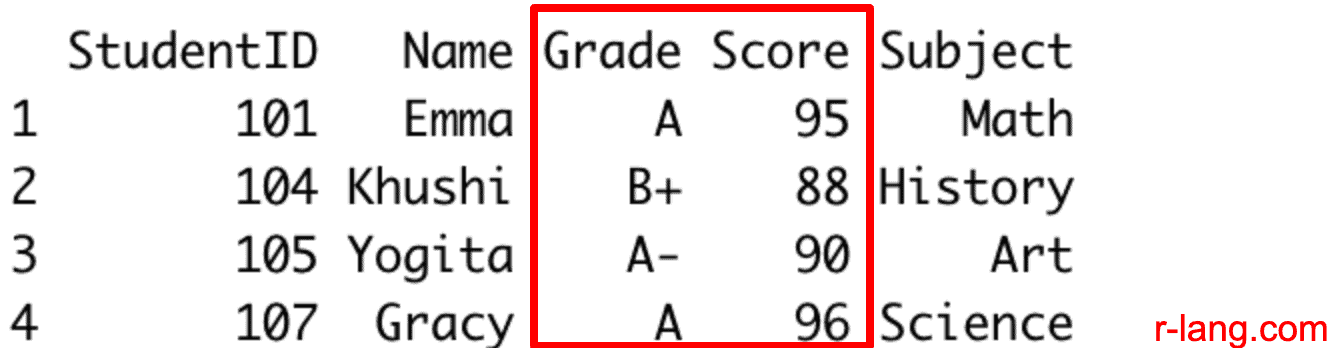
filtered_multiple <- student_grades_df %>% filter(Score > 85 & Subject == "Math")
print(filtered_multiple)
Output
Only one row with StudentID 101 satisfies these conditions.
If you have a scenario in which you have multiple conditions but only at least one of those conditions is TRUE, you should use the | operator inside the filter() function.
Let’s consider conditions where the score exceeds 85 or the grade is exactly A.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
# Multiple Conditions (OR)
filtered_or_rows <- student_grades_df %>% filter(Score > 85 | Grade == "A")
print(filtered_or_rows)Output
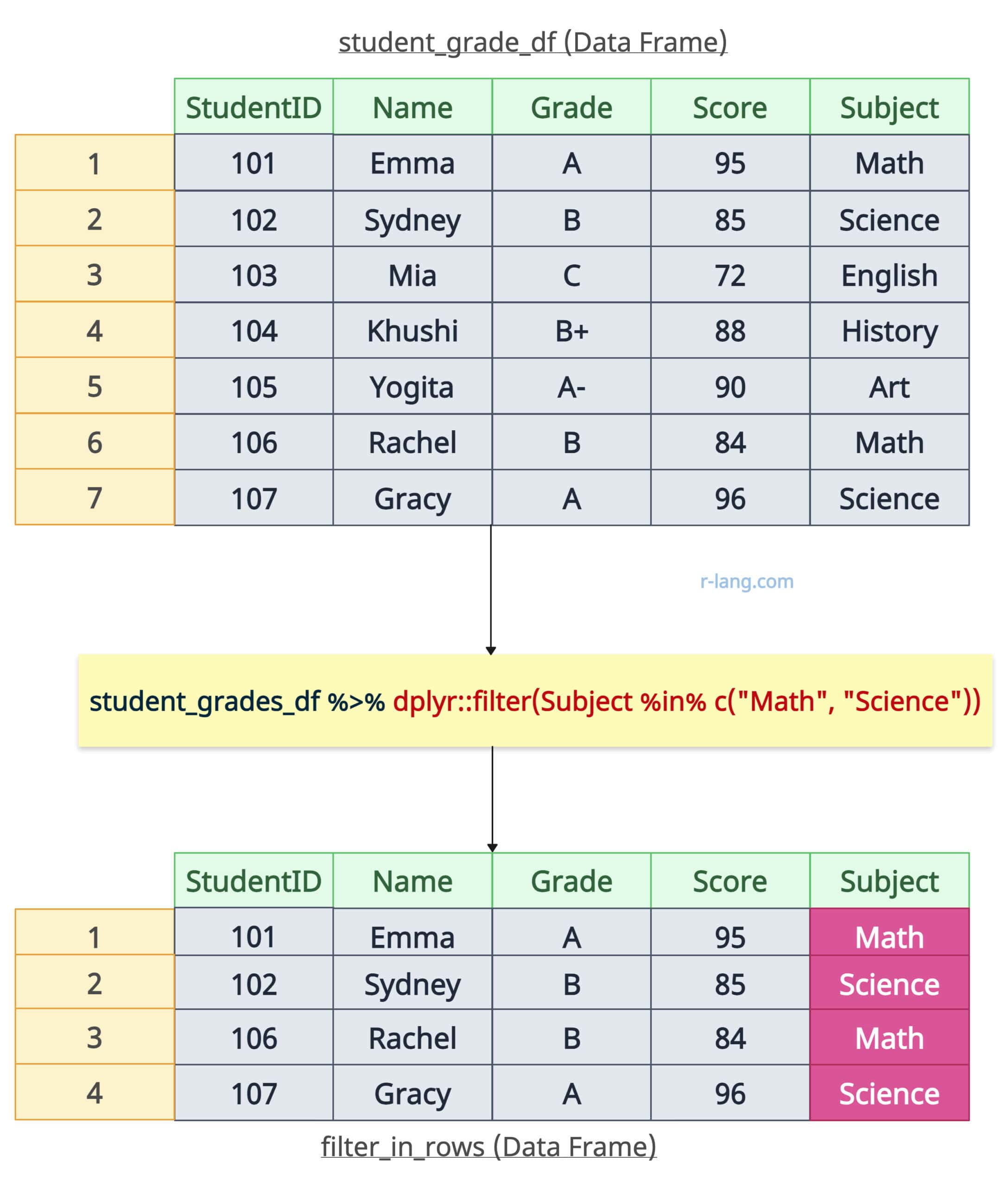
You can use the %in% operator inside the filter() function to select rows where a column’s value matches any value in a given data frame.
Let’s select students that come under Math or Science subjects.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
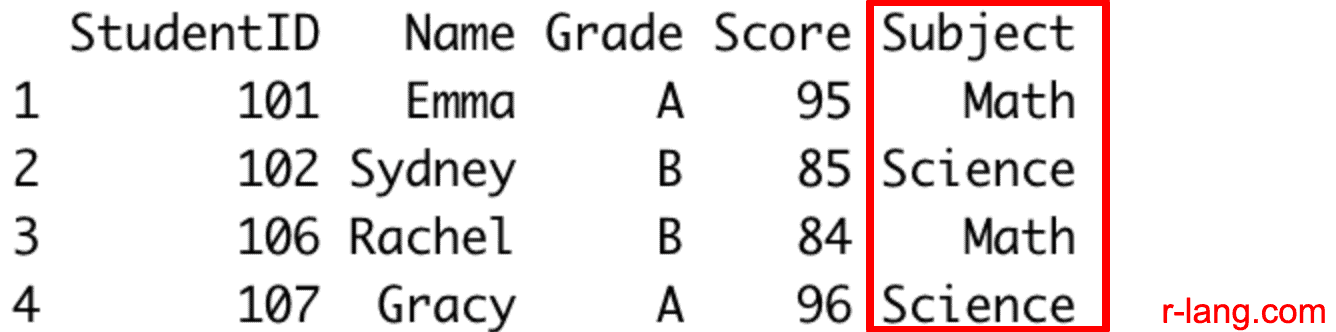
# Filter with %in%
filter_in_rows <- student_grades_df %>% filter(Subject %in% c("Math", "Science"))
print(filter_in_rows)
Output
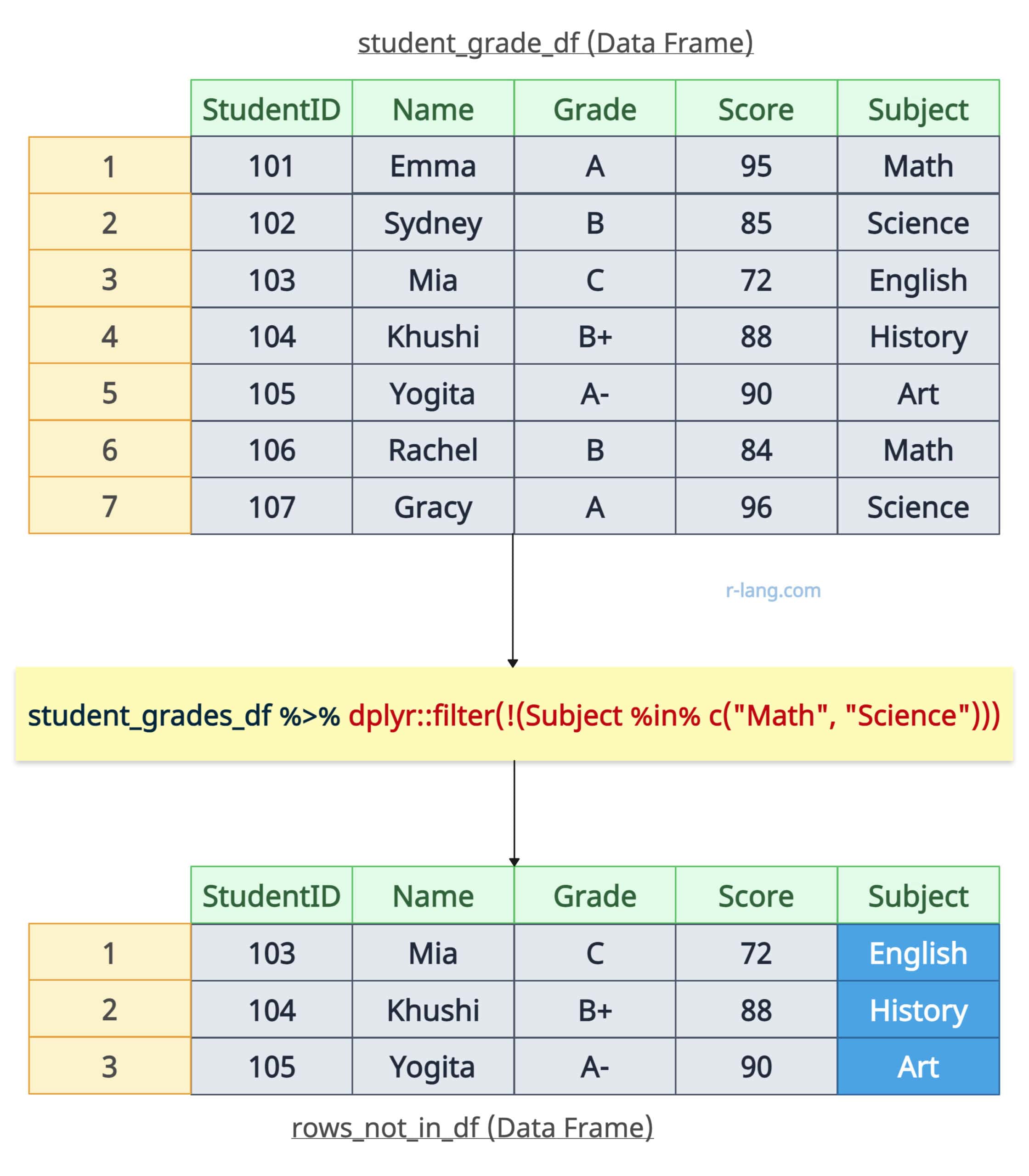
If you want to filter out rows where a column’s values are present in a specific data frame, you can use the “not in” (! %in%) operator with the filter() function.
Let’s filter out rows where students took subjects of Maths or Science. Select all the other rows.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
# Using filter() with "not in" (! %in%)
rows_not_in_df <- student_grades_df %>% filter(!(Subject %in% c("Math", "Science")))
print(rows_not_in_df)
Output
You can create a filter that selects only rows where a string column includes a specific substring using the grepl() or stringr::str_detect() function.
Let’s create a condition that selects only rows with a Name column containing the “i” character.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
# dplyr filter string includes
string_matching_df <- student_grades_df %>% filter(grepl("i", Name, ignore.case = TRUE))
print(string_matching_df)
Output
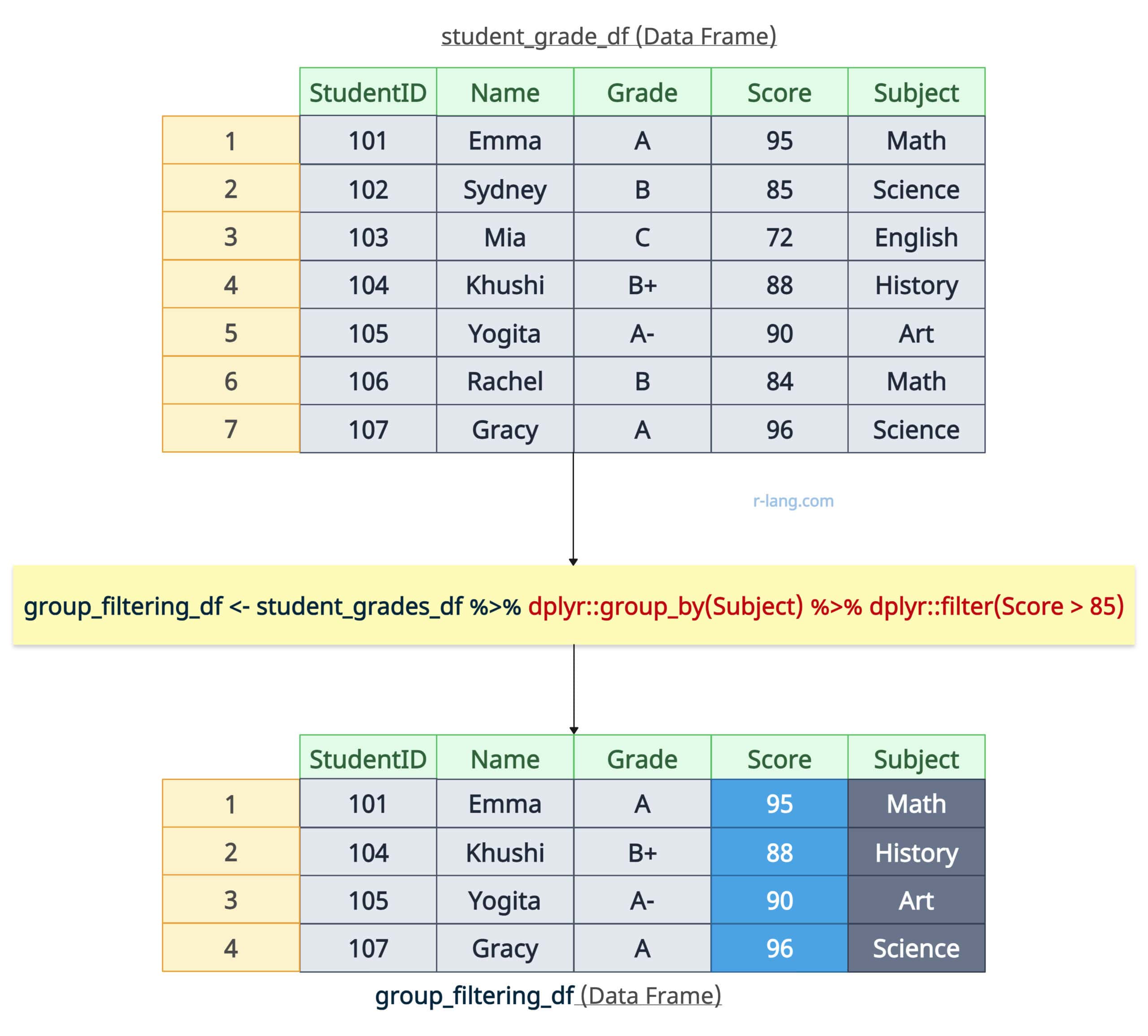
Group filtering is helpful when rows must be filtered based on conditions applied within groups rather than the entire dataset.
Let’s select rows based on the grouping of subjects, and each row contains a score greater than 85.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
# Grouped Filtering
group_filtering_df <- student_grades_df %>%
group_by(Subject) %>%
filter(Score > 85)
print(group_filtering_df)
Output
Please note that here in output, we get the tibble instead of the data frame. We got the records of students whose score is greater than 85 subject-wise. Tibble is an extended version of the data frame.
The dplyr across() function is helpful when filtering based on multiple columns. You can use if_any() or if_all() depending on whether you want to filter rows where at least one or all of the selected columns satisfy a condition.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", "Mia", "Khushi", "Yogita", "Rachel", "Gracy"),
Grade = c("A", "B", "C", "B+", "A-", "B", "A"),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", "English", "History", "Art", "Math", "Science")
)
# Filter Across Multiple Columns
# Keep rows where ALL conditions are met
across_df <- student_grades_df %>% filter(if_all(c(Grade, Score), ~ . > 85))
print(across_df)
Output
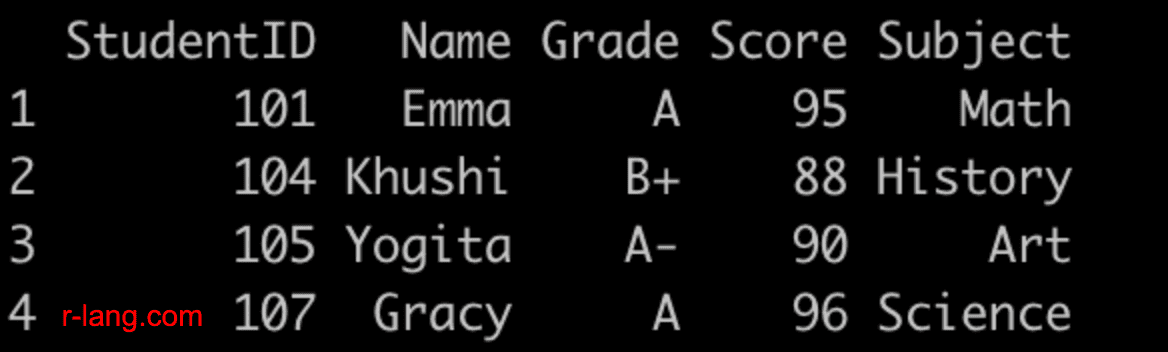
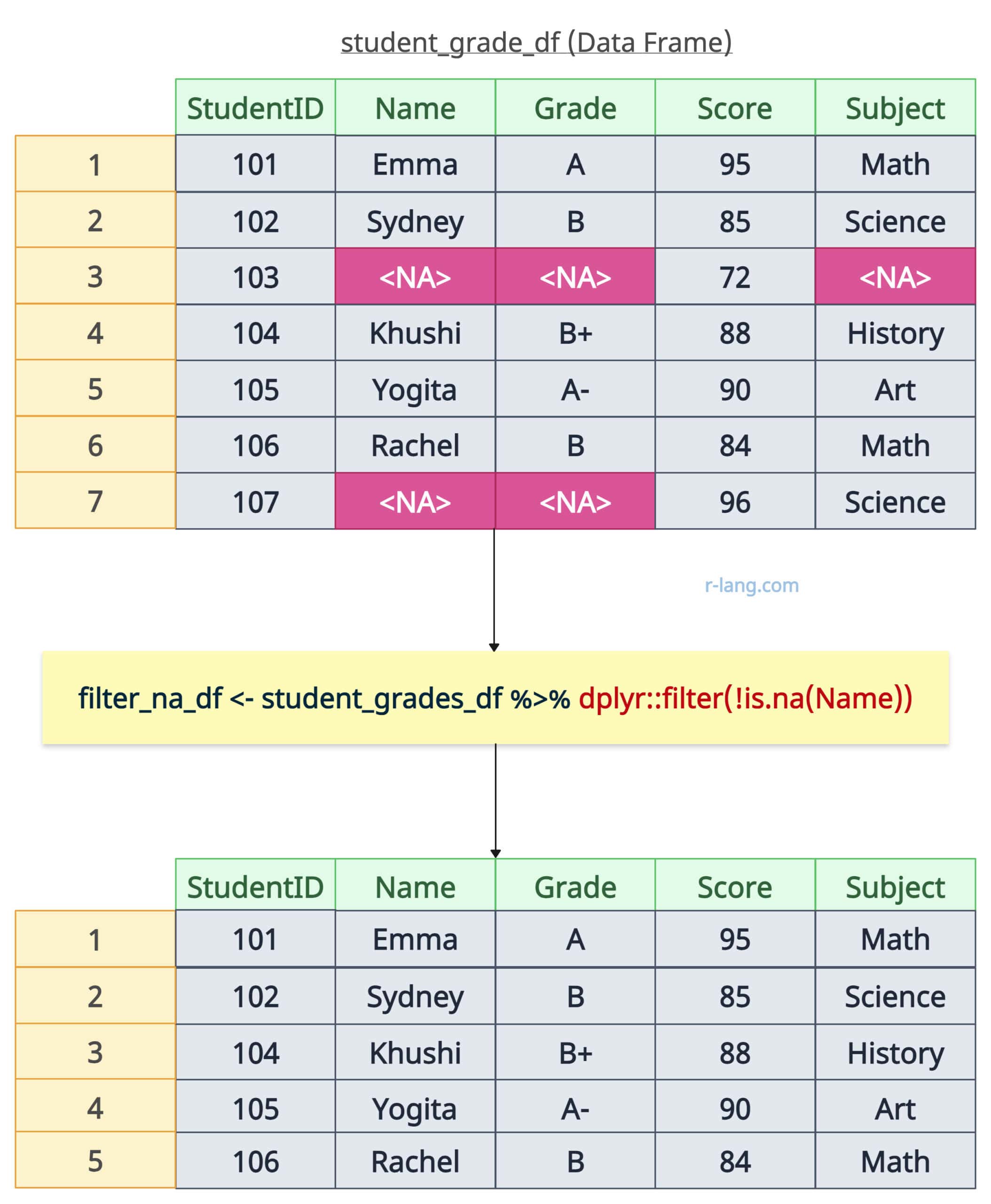
If you want to filter out rows with NA values using the filter() function, you can achieve it by combining it with is.na() function.
library(dplyr)
student_grades_df <- data.frame(
StudentID = 101:107,
Name = c("Emma", "Sydney", NA, "Khushi", "Yogita", "Rachel", NA),
Grade = c("A", "B", NA, "B+", "A-", "B", NA),
Score = c(95, 85, 72, 88, 90, 84, 96),
Subject = c("Math", "Science", NA, "History", "Art", "Math", "Science")
)
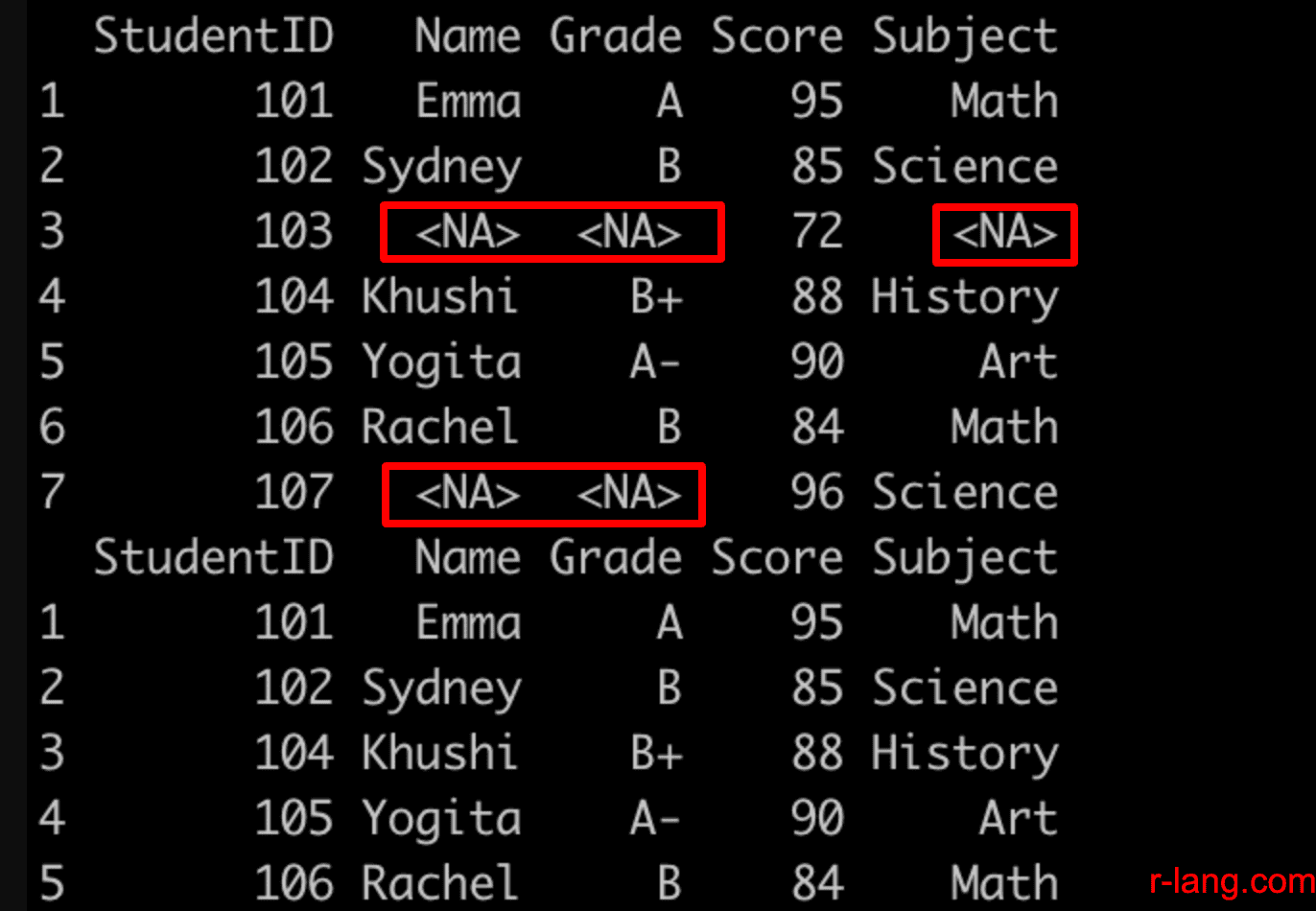
print(student_grades_df)
# Filtering Rows with NA Values
filter_na_df <- student_grades_df %>% filter(!is.na(Name))
print(filter_na_df)
Output
That’s all!
Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.
The scale() function in R centers (subtracting the mean) and/or scales (dividing by the standard…
To rename a file in R, you can use the file.rename() function. It renames a…
The prop.table() function in R calculates the proportion or relative frequency of values in a…
The exp() is a built-in function that calculates the exponential of its input, raising Euler's…
The split() function divides the input data into groups based on some criteria, typically specified…
The colMeans() function in R calculates the arithmetic mean of columns in a numeric matrix,…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}