A vector is a data structure that holds the same type of data. When working with real-time data, it may contain missing data, and it can be represented by NA (not available).
For a proper data analysis, we need to exclude NA values from the vector. Now, you may have one question in your mind. What if each element of a vector contains an NA value? How about that?
Well, if a vector is filled with only NA values, removing NAs will return an empty vector.
If there are no NAs in the vector, it will not alter an input vector, and the output is the same as the input.
Here are three main ways to remove NA values from a Vector in R:
Also, some methods, like sum(), provide an argument called “na.rm = TRUE,” which removes NA before executing sum. However, this method is specific to removing NA values while executing sum and is not a general solution.
The is.na() function detects returns TRUE for each NA value and FALSE otherwise. You can use it to subset the original vector by excluding NA values using this syntax: x[!is.na(x)], where x is a vector.
vec <- c(11, 21, NA, 41, NA, 51)
vec[!is.na(vec)]
# [1] 11 21 41 51In the above code, we directly removed NA values from a vector by subsetting a vector and returning a clean vector. But what do we mean by clean vector? Well, a clean vector does not contain any NA value, and it does not provide any extra attributes.
If the user wants a clean vector quickly, logical indexing is the best approach because it is the fastest.
For code readability, it is fairly obvious that we want to get a vector without NA values just by its syntax.
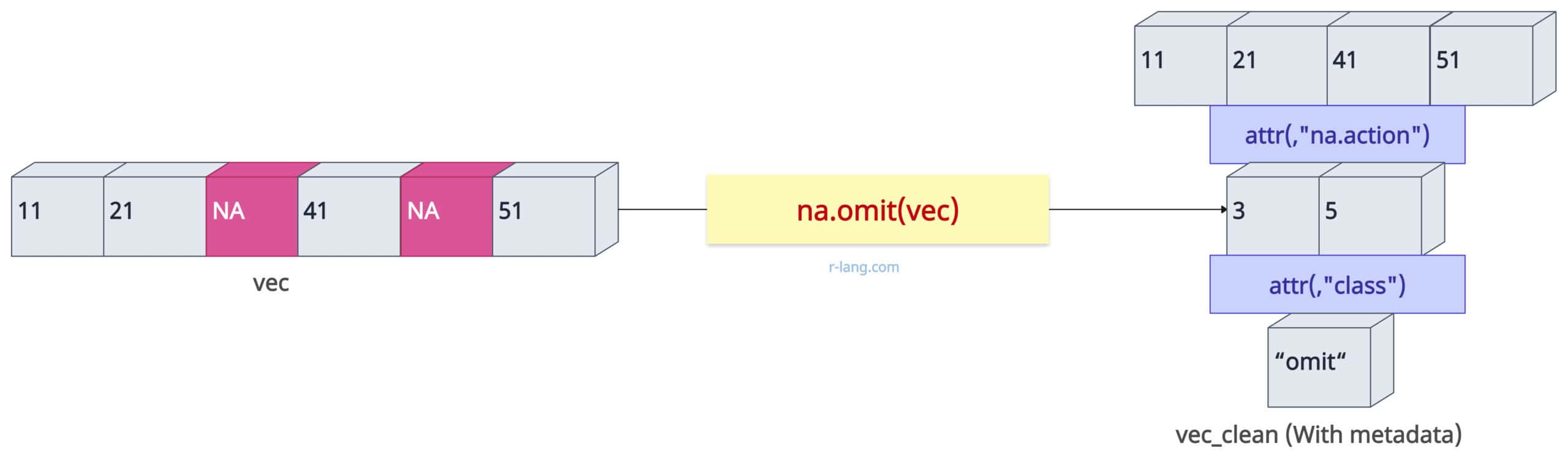
The na.omit() function not only eliminates NA values from an input vector but also returns the vector with an attribute listing omitted positions (attributes are typically ignored in operations).
In the above figure, the upper layer in the output is a vector without NA values. The second layer is the index of NA values, which are 3 and 5, provided by the “na.action” attribute, which can be helpful for debugging.
The class “omit” is part of how R handles these omitted values.
Here is the code implementation:
vec <- c(11, 21, NA, 41, NA, 51)
vec_clean <- na.omit(vec)
vec_clean
# [1] 11 21 41 51
# attr(,"na.action")
# [1] 3 5
# attr(,"class")
# [1] "omit"The main difference between vec[!is.na(vec)] and na.omit() is that the na.omit() function contains metadata, whereas logical indexing does not return any attribute.
If you still want to strip attributes that are not necessary, use this approach: as.vector(na.omit(x))
The complete.cases() method is generally used when we are dealing with a data frame because it returns a logical vector suggesting which rows have no missing values.
However, we can use vec[complete.cases(vec)], where vec is a vector, to delete NA values from a vector and return a clean vector.
vec <- c(11, 21, NA, 41, NA, 51)
vec_clean <- vec[complete.cases(vec)]
vec_clean
# [1] 11 21 41 51You can see that NA values have been filtered out and printed remaining elements in the console.
Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.
The scale() function in R centers (subtracting the mean) and/or scales (dividing by the standard…
To rename a file in R, you can use the file.rename() function. It renames a…
The prop.table() function in R calculates the proportion or relative frequency of values in a…
The exp() is a built-in function that calculates the exponential of its input, raising Euler's…
The split() function divides the input data into groups based on some criteria, typically specified…
The colMeans() function in R calculates the arithmetic mean of columns in a numeric matrix,…
{kind=link}
{kind=link}
{kind=link}