Duplicate rows refer to all the values across all columns that are the same in two or more rows. To avoid redundant data, we must remove duplicates from a data frame. For example, if the same row appears three times in a data frame, we must remove two rows because they are duplicates of one original row.
Here are three ways to remove duplicate rows in an R data frame:
- Using !duplicated()
- Using unique()
- Using dplyr::distinct()
Method 1: Using !duplicated()
By default, the !duplicated() function retains the first occurrence of each row and removes all duplicates. The logical negation (!) helps us subset the data frame and keep the unique rows.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Tejas", "Rushabh", "Dhaval", "Tejas"),
score = c(85, 90, 78, 92, 88, 78, 92, 88),
subject = c("Math", "Math", "History", "History", "Math", "History", "History", "Math"),
grade = c("10th", "11th", "11th", "10th", "10th", "11th", "10th", "10th")
)
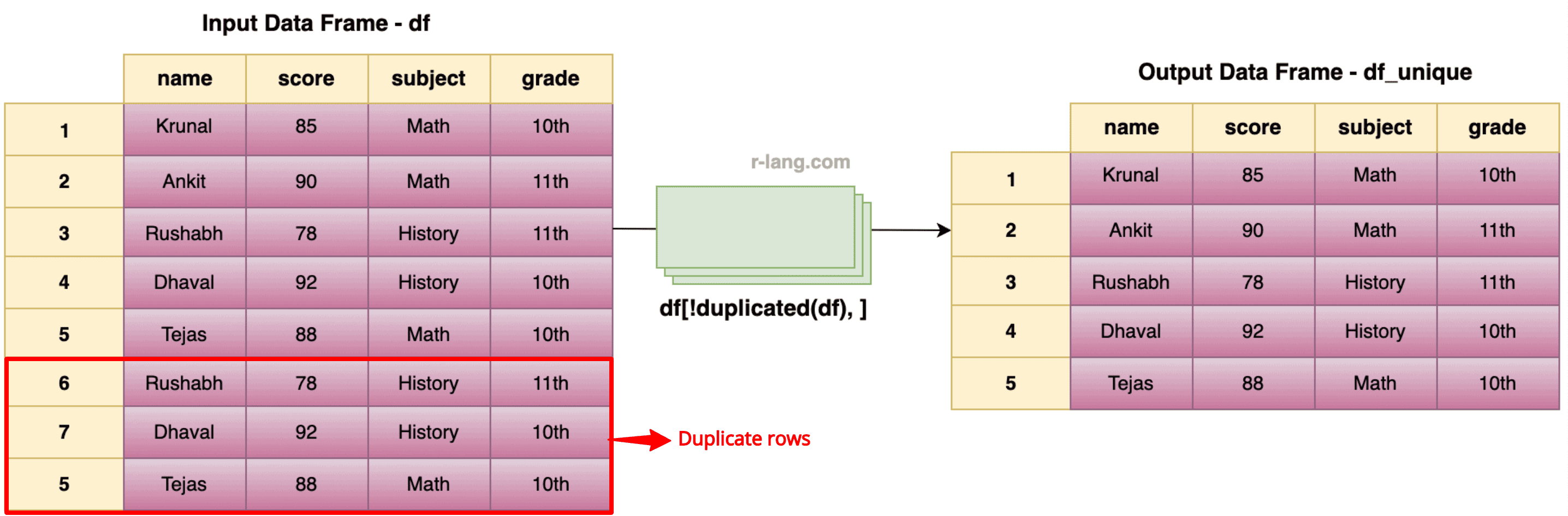
df_unique <- df[!duplicated(df), ]
print(df_unique)
Output
Keeping the last occurrence
You come across a scenario where you need to remove all duplicates except the last one; you can achieve this by passing the “fromLast = TRUE” argument to the duplicated() function.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Tejas", "Rushabh", "Dhaval", "Tejas"),
score = c(85, 90, 78, 92, 88, 78, 92, 88),
subject = c("Math", "Math", "History", "History", "Math", "History", "History", "Math"),
grade = c("10th", "11th", "11th", "10th", "10th", "11th", "10th", "10th")
)
df_unique_last <- df[!duplicated(df, fromLast = TRUE), ]
print(df_unique_last)Output

Removing all occurrences
If you want to remove all occurrences of duplicate rows, you can use the below code:
df_unique_all <- df[!(duplicated(df) | duplicated(df, fromLast = TRUE)), ]Method 2: Using unique()
As the name suggests, the unique() function retains only unique rows and removes all duplicate rows from the Data Frame.
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Tejas", "Rushabh", "Dhaval", "Tejas"),
score = c(85, 90, 78, 92, 88, 78, 92, 88),
subject = c("Math", "Math", "History", "History", "Math", "History", "History", "Math"),
grade = c("10th", "11th", "11th", "10th", "10th", "11th", "10th", "10th")
)
df_unique <- unique(df)
print(df_unique)
Output
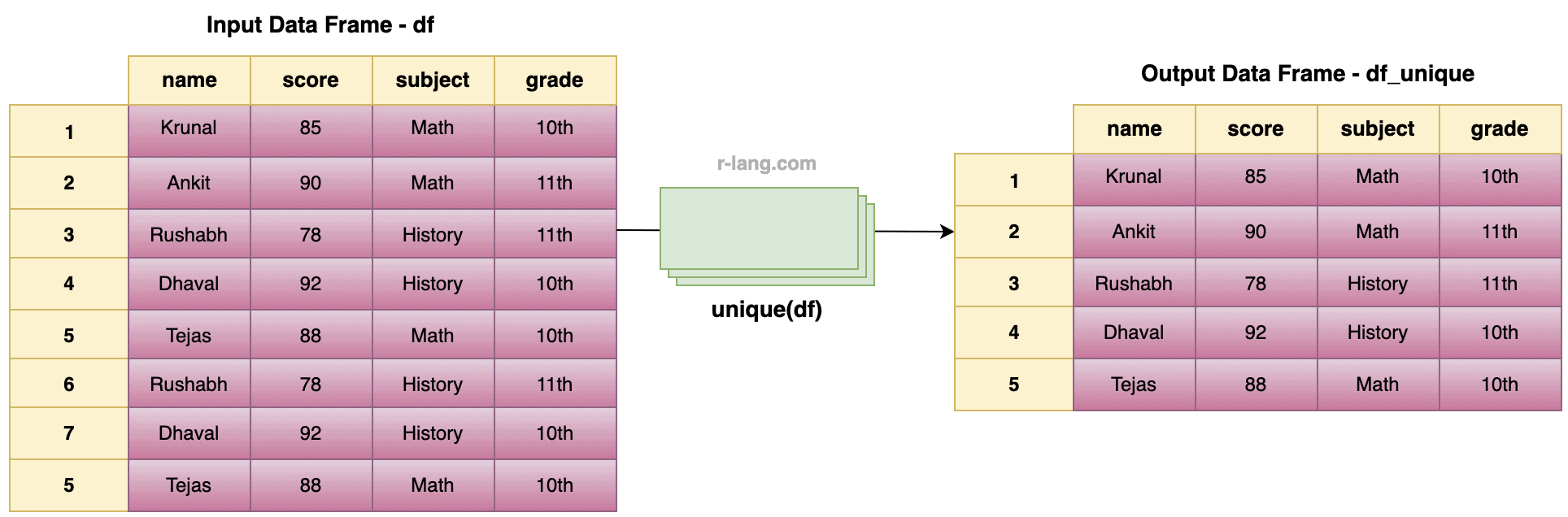
The above image shows that row indexes 6, 7, 8 are duplicated rows, so they have been removed in the output data frame.
Method 3: Using the dplyr package’s distinct() function
The dplyr::distinct() function keeps unique/distinct rows from the data frame. If there are duplicate rows, only the first row is preserved, and the others are removed from the data frame.
library(dplyr)
df <- data.frame(
name = c("Krunal", "Ankit", "Rushabh", "Dhaval", "Tejas", "Rushabh", "Dhaval", "Tejas"),
score = c(85, 90, 78, 92, 88, 78, 92, 88),
subject = c("Math", "Math", "History", "History", "Math", "History", "History", "Math"),
grade = c("10th", "11th", "11th", "10th", "10th", "11th", "10th", "10th")
)
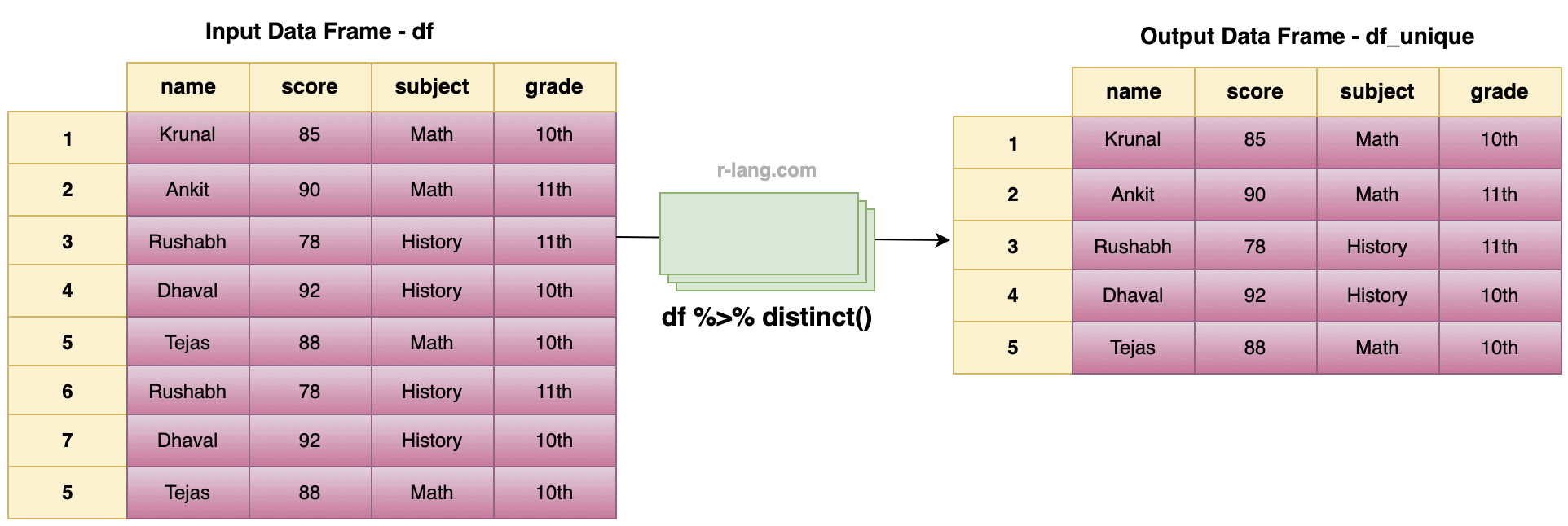
df_unique <- df %>% distinct()
print(df_unique)
Output
Use the following code to remove duplicate rows based on a single column(variable).
df %>% distinct(subject, .keep_all = TRUE)If you want to consider specific columns to determine the duplicate values, you can use `df %>% distinct(col1, col2, .keep_all = TRUE)` to keep all columns but consider only col1 and col2 for duplicates.
The `.keep_all=TRUE` argument is only necessary when we need to specify specific columns and want to retain the other columns in the output.
df %>% distinct(col1, col2, .keep_all = TRUE)It will return the unique rows based on the values of the col1 and col2 columns.
That’s all!

Krunal Lathiya is a seasoned Computer Science expert with over eight years in the tech industry. He boasts deep knowledge in Data Science and Machine Learning. Versed in Python, JavaScript, PHP, R, and Golang. Skilled in frameworks like Angular and React and platforms such as Node.js. His expertise spans both front-end and back-end development. His proficiency in the Python language stands as a testament to his versatility and commitment to the craft.